
HOTの仕組み (1)
NTT オープンソースソフトウェアセンタ 笠原 辰仁
HOTシリーズの第2回です。前回は、HOTの効果をベンチマークの結果を通じて見たところ、性能改善に大きく貢献していることが窺えました。今回はそれをどう実現しているのか、どういう仕組みでHOTが成り立っているのか、を解説していきたいと思います。
前回に見えたHOTの効果は、端的に言うと以下の2つでした。
- 更新処理が速くなった
- ガベージの発生量が減った
では、この2点が実現できた理由を、従来のPostgreSQLと比較しながら見ていきます。
どうして更新処理が速くなったのか?
答えは、「不要なインデックスの更新をスキップするようになったから」です。PostgreSQLは、更新処理が実施された場合に新規データを追加し、既存のデータをそのまま残す(削除されたという情報を付与する)、という処理を行います。この時、バージョン8.2以前のPostgreSQLでは、更新対象のカラム(列)にインデックスが張られていない場合でも、インデックスへのキーの追加が行われていました(図1)。
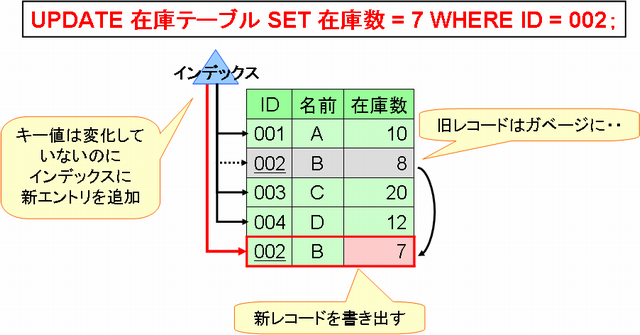
図1. 従来の更新処理
これは、インデックスの値は変わりませんが、データの位置が変わるためです。対して、8.3からはインデックスが張られていないカラムへの更新処理において、追加レコードへのポインタをテーブル内に配置することで、インデックスへのキーの追加をスキップできるようになりました(図2)。
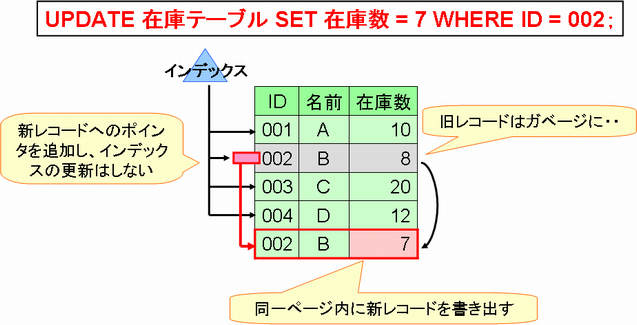
図2. 8.3からのHOT更新処理
つまり、従来はテーブルとインデックスの2つのデータを更新していましたが、8.3からはテーブルのみの更新で済むようになったわけです。単純に考えれば更新のコストが半分下がったことになります。では、この仕組みについてもう少し細かく見てみましょう。
と、その前にインデックスとテーブルの関係を簡単に説明します。
インデックスは、テーブル内のデータを高速に検索するためのものです。インデックスには、インデックスの張られたカラム(IDなど)の情報と、そのカラムを含むレコードの位置が格納されています。インデックスを用いた検索が実施された場合は、該当する値を見つけてその値のカラムをもつレコードをテーブルから取得します。PostgreSQLの場合、上記の「レコードの位置」という情報を「ブロックの位置」と「ブロック内の行へのポインタの位置」として持っています(図3)。「ブロック」とは、PostgreSQLがI/Oを行う単位です。テーブルやインデックスはこのブロック(メモリ上にあるものはページとも呼ばれます)の集合体といったイメージです。ブロックのサイズはデフォルトで8192Byteとなっています。
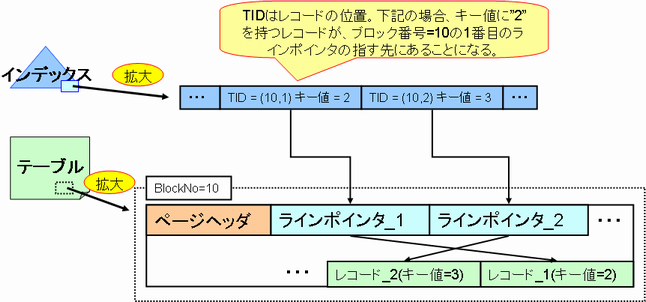
図3. インデックスからテーブルデータを検索する
「ブロック内のレコードへのポインタの位置」を、PostgreSQLではしばしば「ラインポインタ」と言います。従来は、レコードが更新された場合、その新しいレコードの位置を示すラインポインタに行き着くため、インデックスも更新する必要がありました。HOTの改良点は、このラインポインタの情報を別のラインポインタにリダイレクトさせることで、インデックスの更新を不要としたことなのです(図4)。こうすることで、インデックスを更新することなく、新しいデータを検索できるようになりました。
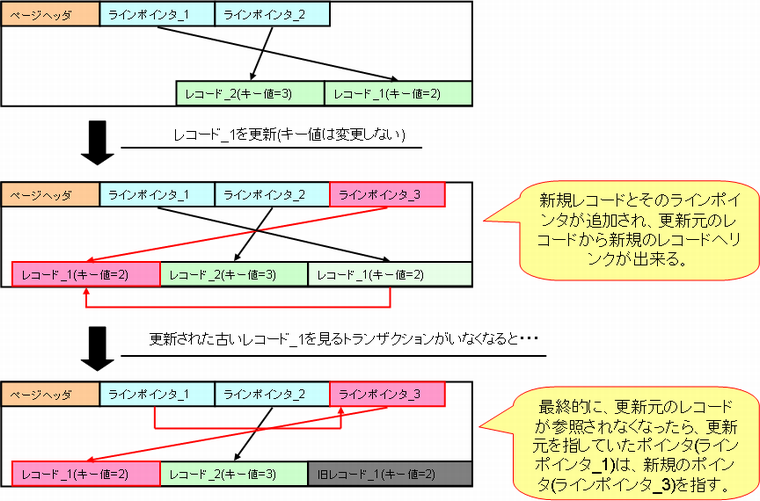
図4. HOTによるラインポインタのリダイレクト
このように、インデックスからは見られていない、テーブル(ヒープ)上にのみ存在する行(タプル)を指して「Heap Only Tuple」と言い、HOTという機能の名称になりました。
ただし、インデックスの張られたカラムの更新処理、つまりインデックスのデータも書き換える必要のある処理には、この方法は適用できません。この場合は、従来どおりインデックスの更新も行われます。しかし、一般的にはインデックスのあるカラムを変更する更新処理はそれほど多くないため、多くの更新処理のケースでHOTの恩恵が受けられると思います。
では、次にガベージの発生量が減った理由について解説します。