
dblink
NTT オープンソースソフトウェアセンタ 板垣 貴裕
他の PostgreSQL データベースを SQL から直接操作できるモジュール "dblink" の使い方を紹介します。 dblink を使うと、分散環境で複数のデータベースをまたがる処理を行ったり、同じサーバ内の別のデータベースを操作することができます。
dblink の構成
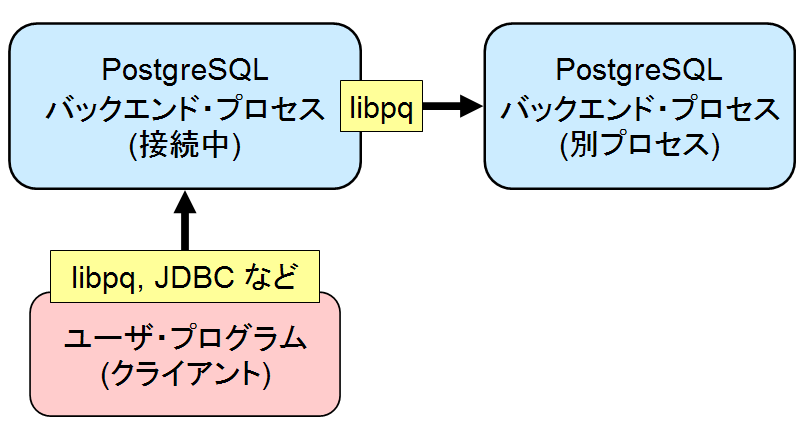
dblink では、接続中のバックエンド・プロセスが別のバックエンド・プロセスに libpq ライブラリを用いて接続します。 このプロセスは、PostgreSQL のサーバプロセスでありながら、クライアントでもあるという構成になっています。 別のバックエンド・プロセスは、同一サーバ(インスタンス)であることもありますし、別マシンの別サーバへ接続することもできます。
基本的な使い方
インストールと簡単な使い方
最初に dblink をインストールします。 RPM からのインストールであれば postgresql-contrib-*.rpm のような名前のパッケージです。 Windows インストーラ等では最初からインストール済みの場合もあります。
拡張モジュール全般に言えることですが、インストールしただけではまだ利用できず、データベースのへの登録が必要です。 今回は dblink を試してみるためにデータベース local と remote を作成し、local 側に dblink を登録します。 $PGSHARE のパスは PostgreSQL のインストール時の設定によります。 RPM では /usr/share/pgsql/、Windows では C:\Program Files\PostgreSQL\(バージョン)\share などが一般的です。
$ createdb local $ createdb remote $ psql local -f $PGSHARE/contrib/dblink.sql
それでは、local DB から remote DB に接続してみましょう。 dblink() には引数の数が異なる複数のバージョンが登録されています。 ここで使った dblink(接続情報, クエリ) は、接続を開き、クエリを実行して結果を返却し、接続を閉じます。 current_database() で "remote" という名前が返っていることから、このクエリは remote DB で実行されたことがわかります。
$ psql local
local=# SELECT * FROM dblink('dbname=remote user=postgres',
'SELECT current_database()') AS t(r text);
r
--------
remote
(1 row)
返却されるレコードの型を 名前(列 型, ...) と明記する必要があります。記述が面倒ですが、SQL 構文の制約上必要なものなので、我慢するしかないようです。 何度も実行する場合には、予めビューを定義しておいても良いかもしれません。
local=# CREATE VIEW remote_database_name AS
SELECT * FROM dblink('dbname=remote user=postgres',
'SELECT current_database()') AS t(r text);
CREATE VIEW
local=# SELECT * FROM remote_database_name;
r
--------
remote
(1 row)
PostgreSQL では、同じ DB インスタンスであっても、ログイン中とは異なるデータベースへは直接 SQL を発行できませんが、dblink を使うとそれができるようになります。 もちろん、remote DB は別の DB インスタンスでも構いません。
外部データベースでのトランザクション
dblink は基本的に自動コミットの動作ですが、BEGIN や COMMIT を発行するとでトランザクションも使えます。このとき、dblink() の呼び出しごとに接続/切断されると困るので、dblink_connect() を使って接続を維持しておきます。 以下の例では、'conn' という名前付きの接続を開き、そこでトランザクションを実行しています。 レコードを返さないコマンドの実行の場合には、dblink() の代わりに dblink_exec() を使うと結果の型を明記せずに済みます。
local=# SELECT dblink_connect('conn', 'dbname=remote user=postgres');
dblink_connect
----------------
OK
(1 row)
local=# SELECT dblink_exec('conn', 'BEGIN');
dblink_exec
-------------
BEGIN
(1 row)
local=# SELECT dblink_exec('conn', 'CREATE TABLE tbl (i integer)');
dblink_exec
--------------
CREATE TABLE
(1 row)
local=# SELECT dblink_exec('conn', 'COMMIT');
-------------
COMMIT
(1 row)
local=# SELECT dblink_disconnect('conn');
dblink_disconnect
-------------------
OK
(1 row)
dblink での問合せは、別のトランザクションとして扱われます。実行中のトランザクションとの整合性を保証するには、二相コミットを使用してください。
また、dblink を他のDBMS製品の機能にある「自律型トランザクション (Autonomous Transactions)」の代わりに使うこともできます。自律型トランザクションとは、現在実行中のトランザクションのコミット結果とは独立した別のトランザクションを実行する機能です。
応用的な利用方法
データベース間の大量のデータコピー
データベース間でデータをコピーする場合には、コピー元からデータをダンプし、コピー先へ再投入する方法が考えられます。 しかし、データの量が多い場合にはダンプファイルを作るのがもったいないと感じるかもしれません。 そのような場合に dblink を使うと、データベース間で直接データコピーができます。
まず、コピー元となるテーブルを remote データベース上に、コピー先になるテーブルを local データベース上に、同じ定義で作成しておきます。
remote=# CREATE TABLE remote_table ( ... ); local=# CREATE TABLE local_table ( ... );
次に、データコピーをする関数を作成するわけですが、その前にテーブルの列定義を抽出するヘルパ関数を作成しておきます。 dblink では、よく結果の列の定義を "AS (...)" の構文で要求されることが多いのですが、この部分を自動化するためにはどうしてもテキストベースの処理を要求されます (PostgreSQL 8.4 現在)。
local=# CREATE FUNCTION get_columndef(regclass) RETURNS text AS
$$
SELECT array_to_string(array_agg(f), ',') FROM
(SELECT quote_ident(attname) || ' ' ||
format_type(atttypid, atttypmod) AS f
FROM pg_attribute
WHERE attrelid = $1
AND attnum > 0
AND NOT attisdropped
ORDER BY attnum) t;
$$
LANGUAGE sql STABLE STRICT;
このヘルパ関数を使って、汎用的なコピー関数を作成してみます。 引数は4つで、コピー先テーブル、接続文字列、リモートで実行するクエリ、一度にフェッチする行数とします。 返値は実際にコピーし行数です。
ここで、dblink() ではなく、dblink_open, dblink_fetch, dblink_close のカーソルを使う関数を使っているところがポイントです。 dblink() だと一気に全件を取得してしまうので、メモリ不足に陥る恐れがあります。 ただ、一度にカーソルで取得する件数が少なすぎると、通信回数が増えて時間がかかる場合があります。 100~1000件くらいの粒度が適する場合が多いようです。
local=# CREATE LANGUAGE plpgsql;
local=# CREATE FUNCTION insert_from_remote(
insert_into regclass,
conninfo text,
remote_query text,
num_fetch integer)
RETURNS bigint AS
$$
DECLARE
local_query text;
rows bigint;
total_rows bigint := 0;
BEGIN
local_query := 'INSERT INTO ' || insert_into::text ||
' SELECT * FROM dblink_fetch(''copy_conn'', ''copy_cur'', ' ||
num_fetch || ') AS (' || get_columndef(insert_into) || ')';
PERFORM dblink_connect('copy_conn', conninfo);
PERFORM dblink_open('copy_conn', 'copy_cur', remote_query);
LOOP
EXECUTE local_query;
GET DIAGNOSTICS rows = ROW_COUNT;
IF rows = 0 THEN
EXIT;
END IF;
total_rows := total_rows + rows;
END LOOP;
PERFORM dblink_close('copy_conn', 'copy_cur');
PERFORM dblink_disconnect('copy_conn');
RETURN total_rows;
END;
$$
LANGUAGE plpgsql STRICT;
それでは、SELECT * FROM remote_table の結果を、local_table へコピーしてみましょう。 テーブルの定義が必要な箇所はヘルパ関数で吸収しているため、異なる定義のテーブルにも適用できる汎用的なコピー関数として使えます。
local=# SELECT insert_from_remote('local_table',
'dbname=remote', 'SELECT * FROM remote_table', 1000);
insert_from_remote
--------------------
10000
(1 row)
複数サーバでの一括集計処理
dblink は非同期クエリもサポートしています。 これを使うと、複数のサーバへ同時に SQL を発行し、さらに結果をまとめて集計する処理を作ることができます。
CREATE FUNCTION twophase_avg(conninfo text[]) RETURNS numeric AS
$$
DECLARE
i integer;
r_count numeric;
r_sum numeric;
BEGIN
-- 1段階目の集計処理を非同期クエリとして送信する.
FOR i IN array_lower(conninfo, 1) .. array_upper(conninfo, 1) LOOP
PERFORM dblink_connect('conn_' || i, conninfo[i]);
PERFORM dblink_send_query('conn_' || i,
'SELECT count(*), sum(i) FROM remote_table');
END LOOP;
-- 結果を待つ.
r_count := 0;
r_sum := 0;
FOR i IN array_lower(conninfo, 1) .. array_upper(conninfo, 1) LOOP
SELECT r_count + c, r_sum + s
INTO r_count, r_sum
FROM dblink_get_result('conn_' || i) AS (c numeric, s numeric);
END LOOP;
-- 切断する.
FOR i IN array_lower(conninfo, 1) .. array_upper(conninfo, 1) LOOP
PERFORM dblink_disconnect('conn_' || i);
END LOOP;
-- 2段階目の集計を行う.
RETURN r_sum / r_count;
END;
$$
LANGUAGE plpgsql;
以下のように host A, B, C に同時にクエリを発行し、その結果をさらに手元のデータベースで集計します。 host A, B, C での処理は複数のサーバで並列に行われるため、大容量のデータを処理する場合には高速化が望めます。
=# SELECT twophase_avg(ARRAY['host=A', 'host=B', 'host=C']);
twophase_avg
---------------------
12.1666666666666667
(1 row)
おわりに
もちろん dblink を使わなくても、プログラミング言語を使って複数の PostgreSQL サーバへアクセスするプログラムを作成すれば等価なことはできるのですが、dblink をビューやユーザ定義関数の「裏方」として使うことで、複数のデータベースの連携処理を、PostgreSQL だけでパッケージングできるのが利点です。
また、dblink の姉妹品として、PL/Proxy というアドオンも紹介しておきます。 dblink では 1台の PostgreSQL サーバをプロキシとして使って、他のサーバへ処理を振り分けるような使い方もできますが、PL/Proxy はそういったプロキシ用途に特化したストアド言語です。