
ストリーミング・レプリケーションの構築
FORCIA, Inc. 板垣 貴裕
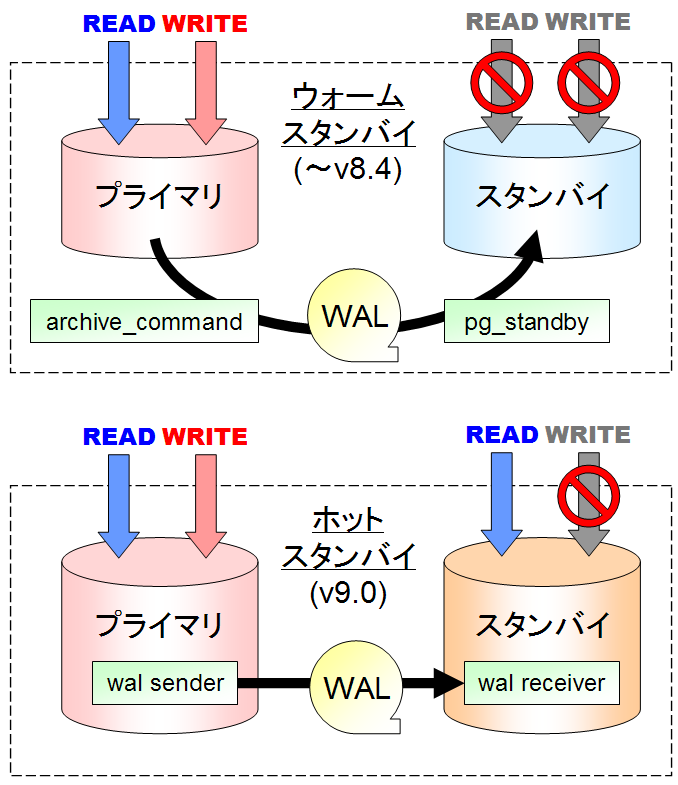
ストリーミング・レプリケーションと
ウォームスタンバイの比較
ストリーミング・レプリケーション (Streaming Replication) は、PostgreSQL 9.0 以降で利用できる、本体組み込みのレプリケーション機能です。参照/更新が可能な1つのマスタDBへの更新操作を、参照のみが可能な複数のスタンバイDBへ転送することで、データベースを複製することができます。スタンバイDBに更新結果が反映されるまでには若干の遅延がありますが、比較的 遅延は少なく、マスタDBへの影響も小さいレプリケーション方式です。
用途
ストリーミング・レプリケーションには以下の用途があります。
- 多数の参照クエリのサーバ間分散
- マスタDB異常時の迅速なフェイルオーバー (切り替え)
- マスタDBのディスク故障に備えたリアルタイム・バックアップ
PostgreSQL 9.1 での強化点
バージョン 9.0 の目玉機能として登場したレプリケーション機能ですが、9.1 ではさらに以下が強化されました。
- 同期レプリケーション (更新結果の到着保証)
- ベース・バックアップの簡略化 (初回のデータ複製用ツール)
- レプリケーションの状態を確認するためのシステム・ビュー
- フェイルオーバーのサポート強化 (専用コマンド, 別のマスタ・サーバに再接続)
それでは、レプリケーションを利用したクラスタ構成を、その手順に沿って見ていきましょう。 以下の説明では、マスタとスタンバイのDBクラスタのパスを以下のように置き換えています。 ただし、実際の設定ファイル中には$表記のエイリアスは使えないことに注意してください。
- $PGDATA_MASTER : マスタのDBクラスタのパス
- $PGDATA_STANDBY : スタンバイのDBクラスタのパス
マスタDBがまだ無ければ作成して、サービスも起動しておきます。
$ initdb --no-locale --encoding=UTF8 -D $PGDATA_MASTER $ pg_ctl start -D $PGDATA_MASTER
1. ユーザの作成と接続設定
PostgreSQL 9.1 では、レプリケーションやホット・バックアップに、必ずしも管理者ユーザが必要なくなりました。 代わりに、一般ユーザに REPLICATION 権限を与えることができます。 バックアップに管理者権限が不要になったため、マスタデータの不正な改変を防ぐことができ、セキュリティが向上したと言えるでしょう。 9.0 では代わりに管理者ユーザを使う必要があります。
[レプリケーション用ユーザの作成] $ psql -p 5432 -d postgres =# CREATE ROLE repl_user LOGIN REPLICATION PASSWORD '...';
次に、そのユーザに replication という名前の仮想データベースへの接続権限を与えます。pg_hba.conf に設定を追加してください。 以下の例では手軽に試せるよう、マスタとスタンバイは同一サーバ (localhost) を想定しています。 実際の運用では、ADDRESS にはスタンバイ・サーバのアドレスを指定してください。 また、フェイルオーバー後にマスタとスタンバイを入れ替える運用をする場合には、マスタ自身のアドレスも追加しておくと良いでしょう。
[$PGDATA_MASTER/pg_hba.conf] # TYPE DATABASE USER ADDRESS METHOD # IPv4 local connections: host all all 127.0.0.1/32 trust host replication repl_user 127.0.0.1/32 md5 # IPv6 local connections: host all all ::1/128 trust host replication repl_user ::1/128 md5
2. マスタへの初期データ投入
まだレプリケーションを始める前の段階ですが、性能面で重要なことなので、あえて節を設けます。
初期データ投入では、大量の更新 (INSERT, COPY FROM) が発生しますが、レプリケーションしていない状態で行ったほうが高速です。ここで、「レプリケーションしていない」とは、単にスタンバイが接続していないだけでなく、専用の「レプリケーションできないが高速データ投入可能」な状態を指します。
専用の設定を使う利点は、記事「WALをスキップして高速化する」で説明しています。 設定パラメータとしては、以下のような値を使うことになります。
[$PGDATA_MASTER/postgresql.conf (データ投入用)] wal_level = minimal max_wal_senders = 0 archive_mode = off #hot_standby = on # 後で必要なので、ここで前もって設定してもOK
この例では、pgbench を利用して適当なデータを投入しておきます。
$ pgbench -p 5432 -i
また、初期データロードが完了したら、データベース全体の VACUUM ANALYZE (vacuumdb --all --analyze) をしておきましょう。
3. マスタのパラメータ設定
初期データロードが完了したら、レプリケーション用の設定に変更します。 ただし、その前に WALアーカイブを使うか否かを決めておきましょう。
WALアーカイブをする場合
スタンバイDBの反映処理が追いつかない場合、もしくは長期間の停止後に再開した場合などに、アーカイブされたWALファイルを使ってマスタDBに追いつけることが利点です。 また、WALアーカイブはポイント・イン・タイム・リカバリ (PITR) でも必要なため、データの確実な復旧が要求される用途では、どのみちWALアーカイブを使うことになるかもしれません。
欠点は、WALアーカイブ用のファイル置き場を用意する必要があることです。 このファイル置き場の選択には、意外と注意が必要です。 マスタとスタンバイの両DBから参照可能でなければなりませんし、アーカイブWALが必要になったとき、マスタが故障している可能性 (ディスク破損, OSが起動しない) があることも考慮すると、DBとは別のファイルサーバを用意するのが確実かもしれません。 さらに、WALアーカイブ置き場のディスク容量不足を避けるため、十分に古いWALアーカイブを定期的に削除するよう設定が必要です。
WALアーカイブをしない場合
WALアーカイブ用のファイル置き場の確保やメンテナンスが難しい場合には、WALアーカイブをしないという選択肢もあります。ただ、スタンバイDBへの更新反映が遅れすぎた場合に、追いつき処理を「諦めて」しまう欠点があります。 追いつけなくなっても、エラーにはならず、参照は引き続き可能ですが、それ以降は更新が反映されません。再度追いつくには、データベースの複製からやり直しが必要です。
アーカイブしない場合、ある程度の期間は追いつきが可能なように、wal_keep_segments を少し増やしておくとよいでしょう。
[$PGDATA_MASTER/postgresql.conf (レプリケーション用)] wal_level = hot_standby max_wal_senders = 2 # スタンバイDBの数 + 1 # アーカイブ使用時 archive_mode = on archive_command = '...' # アーカイブ不使用時 archive_mode = off wal_keep_segments = 8 # 8-32 が目安
max_wal_senders には「スタンバイDBの数 + 1」を設定しておきます。 +1 は、レプリケーション中に再度ベース・バックアップを取得する必要が生じた場合の保険です。
設定ファイルを書き換えたら、マスタDBを再起動します。
$ pg_ctl restart -D $PGDATA_MASTER
4. ベース・バックアップの取得
次に、スタンバイDB用のデータベース全体の複製を作成します。 専用のツールとして、PostgreSQL 9.1 には pg_basebackup コマンドが追加されました。 pg_dump 並みの手軽さで、PITR やレプリケーションのためのバックアップを作成できます。 管理者権限も不要で、遠隔サーバのバックアップにも対応しています。 複数のテーブルスペースがある場合にも一括してバックアップしてくれるのでお手軽です。
pg_basebackup には、マスタDBのホスト (-h)、ポート (-p)、接続ユーザ (-U)、バックアップ先パス (-D) の他、以下のオプションが指定できます。 この他にもバックアップを .tar 形式で取得するオプションもあります。
- -x, --xlog
- バックアップにWALファイルを含めます。レプリケーション用ではなく、最小構成のオンライン・バックアップ (PITR無し) を行うには、このオプションを含めてください。
- -c, --checkpoint=fast|spread
- fast にするとバックアップ前のチェックポイントにかかる時間を短縮できますが、瞬間的にマスタDBの I/O 負荷が高まるかもしれません。
- -P, --progress
- バックアップの進捗を表示します。
$ pg_basebackup -h localhost -p 5432 -U repl_user -D $PGDATA_STANDBY \
--xlog --checkpoint=fast --progress
Password:
34987/34986 kB (100%) 1/1 tablespaces
NOTICE: WAL archiving is not enabled; you must ensure that all required
WAL segments are copied through other means to complete the backup
--progress で表示されるバイト数の分子が分母より大きくなってしまっていますが、サイズはあくまで推定値なので、バックアップ中にDBサイズが増加した場合は、100% を超えることもあるようです。
NOTICE のメッセージは、--xlog を指定しない場合に出力されます。 「WAL が無いままだと復旧できませんよ」という意味です。 今回はストリーミング・レプリケーションで WAL をマスタDBから送ってもらいます。 WALアーカイブを使っている場合には、アーカイブからもWALを持って来れます。
5. スタンバイのパラメータ設定
postgresql.conf に関しては、hot_standby = on を追加で指定する他は、基本的にはマスタDBと同じ設定ファイルを使って問題ありません。 ただ、今回の例ではマスタと同一サーバを使うことから、ポート番号が被らないよう 5433 に変更しておきます。
[$PGDATA_STANDBY/postgresql.conf] port = 5433 # 今回のサンプル手順でのみ; 通常は変更不要 hot_standby = on
次に、recovery.conf を作成します。 最低限必要なのは standby_mode を on にし、primary_conninfo にマスタDBへの接続文字列を設定することです。
[$PGDATA_STANDBY/recovery.conf] standby_mode = 'on' primary_conninfo = 'host=localhost port=5432 user=repl_user password=...'
2つのファイルを作成したら、スタンバイDBを開始します。
$ pg_ctl start -D $PGDATA_STANDBY ... LOG: entering standby mode --(1) ... LOG: database system is ready to accept read only connections --(2) LOG: streaming replication successfully connected to primary --(3)
起動直後のログの中に上記の3行 「(1) スタンバイモードとして起動」「(2) 参照のみを受け付ける準備ができた」「(3) ストリーミング・レプリケーションが開始した」があることを確認します。
6. レプリケーション状態の確認
PostgreSQL 9.1 では、レプリケーションの状態を確認するシステム・ビューや関数が多数追加されました。 それらを使って、レプリケーションの状態を確認してみます。
まずは、マスタDBで適当な更新処理を実行します。
$ pgbench -p 5432 -T 180
レプリケーション中、マスタDBでは pg_stat_replication を利用して状態を確認できます。下記の表示例では、replay_location が sent_location よりも若干値が小さいことが確認できます。この差が、非同期レプリケーションの遅れに相当します。ただし、スタンバイからの報告にも遅延があるため、実際の遅れはもっと小さい場合も多いようです。もし一致していれば、全く遅れが無いことがわかります。
$ psql -x -p 5432 -c "SELECT * FROM pg_stat_replication" -[ RECORD 1 ]----+------------------------------ procpid | 10269 usesysid | 16384 usename | repl_user application_name | walreceiver client_addr | ::1 client_hostname | client_port | 38999 backend_start | 2011-04-25 23:16:32.818739+09 state | streaming sent_location | 0/5053EC8 write_location | 0/5053EC8 flush_location | 0/5053EC8 replay_location | 0/5053CA8 sync_priority | 0 sync_state | async
状態をざっくり確認するために便利なのが state 列です。通常、オンライン中は streaming であることが期待されます。
startup: 接続の確立中backup: pg_basebackup によるバックアップの実施中catchup: 過去の更新を反映中streaming: 更新をリアルタイムに反映中
一方、スタンバイDBでは pg_last_xact_replay_timestamp() 関数を使って、マスタDBでのどの時点の処理までが反映されたかを確認できます。 ただし、この時間は「処理が行われた時刻」であるため、しばらく更新処理が無いと、過去の時刻を指し続けます。現在時刻よりも遅れていても、必ずしもレプリケーションの遅延があるわけではありません。「マスタDBのこの時刻までの更新結果は反映された」と解釈してください。
$ psql -p 5433 -c "SELECT pg_last_xact_replay_timestamp()" pg_last_xact_replay_timestamp ------------------------------- 2011-04-25 23:20:56.912261+09 (1 row)
一方、9.0 ではSQLから利用可能な機能が限定されており、シェルから ps を使って確認する必要があります。wal sender process (マスタDB) と wal receiver process, startup process (スタンバイDB) の各プロセスが存在することで、レプリケーションが行われていることを確認できます。
$ ps x | grep postgres ... $PGHOME/bin/postgres -D $PGDATA_MASTER ... $PGHOME/bin/postgres -D $PGDATA_STANDBY ... postgres: startup process recovering 000000010000000000000005 ... postgres: wal receiver process streaming 0/51EC508 ... postgres: wal sender process repl_user ::1(38999) streaming 0/51EC508 ...
7. フェイルオーバー
スタンバイDBでは参照しかできませんが、マスタDBから切り離して更新可能な状態に「昇格 (promote)」することができます。 フェイルオーバーの際には、スタンバイのうちの1つをマスタに昇格することになります。
まずは、マスタDBを疑似的にクラッシュさせてみましょう。 immediate モードで停止することで、クラッシュした状況を作り出せます。
$ pg_ctl stop -m immediate -D $PGDATA_MASTER
スタンバイは、マスタから切断されたことは検知しますが、そのまま待機します。 PostgreSQL 本体には自動フェイルオーバー機能は無いので、Pacemaker 等の高可用ミドルウェアや、pgpool-II の管理機能を組み合わせる必要があります。
待機中も引き続き参照できますが、更新はできません。 スタンバイをマスタに昇格するために、9.1 では専用のコマンド pg_ctl promote が追加されました。 9.0 では、代わりに recovery.conf で trigger_file を設定し、トリガファイルを作成してください。 pg_ctl promote のほうが手間がかかりませんし、トリガファイルよりも若干ですが短時間で昇格できます。
$ psql -p 5433 -c "CREATE TABLE tbl (i integer)" ERROR: cannot execute CREATE TABLE in a read-only transaction $ pg_ctl promote -D $PGDATA_STANDBY server promoting $ psql -p 5433 -c "CREATE TABLE tbl (i integer)" CREATE TABLE
promote 後は更新処理 (テーブルの作成) が成功するようになることが分かります。
8. マスタとスタンバイの交換
次に、マスタとスタンバイの役割を交換 (入れ替え) して、再び2台構成に復旧することを考えます。 旧マスタDBを、新マスタDBのスタンバイとして再接続してみましょう。 旧マスタの postgresql.conf を編集し、recovery.conf を作成します。 このとき、注意する点が2つあります。
1つ目は、recovery_target_timeline='latest' を指定することです。 フェイルオーバーした新しいマスタでは Timeline ID が変更されており、その新しい Timeline ID に追従する必要があるためです。
2つ目は、restore_command を指定することです。 WALファイルはストリーミングされるのですが、バックアップ履歴ファイル (.history) はストリーミングされないため、別途コマンドで転送する必要があります。
以下ではまだ $PGDATA_MASTER の名前になっていますが、実際には既にマスタとスタンバイは入れ替わっていることに注意してください。また、本例では同一マシン上なので restore_command は cp を使っていますが、ネットワーク上の別マシンの場合は scp 等を使うことになります。
[$PGDATA_MASTER/postgresql.conf] hot_standby = on
[$PGDATA_MASTER/recovery.conf] standby_mode = 'on' primary_conninfo = 'host=localhost port=5433 user=repl_user password=...' recovery_target_timeline='latest' restore_command = 'cp $PGDATA_STANDBY/pg_xlog/%f "%p" 2> /dev/null'
その後、新たなスタンバイとして再起動します。
$ pg_ctl start -D $PGDATA_MASTER LOG: restored log file "00000002.history" from archive LOG: entering standby mode LOG: restored log file "000000010000000000000003" from archive LOG: redo starts at 0/30000B0 LOG: restored log file "000000020000000000000004" from archive LOG: consistent recovery state reached at 0/46DCB90 LOG: database system is ready to accept read only connections LOG: record with zero length at 0/46EECF8 LOG: streaming replication successfully connected to primary
これで、マスタをスタンバイに再接続することができました!
ただし、マスタがクラッシュした時点で、スタンバイに転送していないWALが残っていた場合、レプリケーション中にエラーになる場合があります。 その場合は、この手順では復旧できないため、ベース・バックアップからやり直す必要があります。 マスタDBをそのまま使う場合には、フェイルオーバー (異常終了後の切り替え) ではなく、スイッチオーバー (正常終了後の切り替え) に留めておいたほうが良いかもしれません。 2つ以上のスタンバイDBがある場合に、新マスタDBに繋ぎ直す際にも、新マスタDBはスタンバイの中で「最もトランザクションのリプレイが先行した」ものを選ぶ必要があります。
Timeline ID という用語がでてきました。 直訳すると「時系列ID」ですが、どちらかというと「平行世界の世界ID」とでも表現したほうが誤解が無いかもしれません。
新マスタに昇格したDBでは、旧マスタDBとは独立して更新を行えます。 そのため、旧マスタDBとは「異なる歴史」を辿ることになるわけです。 フェイルオーバー後、新マスタDBに接続するためには、この新しい世界が「どれ」になるのかを指定する必要が生じます。 'latest' は、そのマスタでの現在利用中の ID を指定したことになります。
まとめ
PostgreSQL 9.1 では、ストリーミング・レプリケーションの手間を抑えるツールや機能が整備され、手順を一般化できるようになりました。 pg_basebackup ツールによる初回のDB複製の自動化、pg_stat_replication による集中監視、pg_ctl promote オプションによるフェイルオーバーと、PostgreSQL でレプリケーション・クラスタを構築する上で必要な要素が整理されました。
これ以外にも、pgpool-II と組み合わせて参照クエリを自動的に分散させることもできるので、参考にしてみてください。
また、新機能である「同期レプリケーション」については、別途ページを設けて解説していきます。
関連リンク
- PostgreSQL文書: ストリーミングレプリケーション
- PostgreSQL 9.0 ストリーミングレプリケーションの実力 (PostgreSQL Conference 2011)
- 5ステップで始めるPostgreSQLレプリケーション (永安悟史 氏)
- レプリケーション勉強会 自習用テキスト (しくみ勉強会 2010年8月, 藤井雅雄 氏、笠原辰仁 氏)
- PostgreSQL 9.0 - Streaming Replication: 機能一覧, 仕組み (InterDB)