
pgbenchの使いこなし
SRA OSS, Inc. 日本支社 石井 達夫
pgbenchとは
pgbenchはPostgreSQLに同梱されているシンプルなベンチマークツールです。最初のバージョンは筆者により作成され、日本のPostgreSQLメーリングリストで1999年に公開されました。その後pgbenchはcontribという付属追加プログラムとして、PostgreSQLのソースコードとともに配布されるようになりました。どのバージョンでPostgreSQLに取り込まれたのかはPostgreSQL付属のドキュメント(HISTORY)には書かれていないので定かではないのですが、コミットログを見ると、おそらく2000年にリリースされたPostgreSQL 7.0で導入されたと思われます。その後数多くの改良がたくさんの人によって行われ、現在に至っています。
pgbenchを利用することにより、自分の使っているPostgreSQLの性能を数値で把握することができるようになり、チューニングの結果を確認したり、ハードウェアをアップグレードしたときの効果を客観的に見ることが可能です。
ただし、pgbenchは厳密な意味でのベンチマークツールではありません。TPC(http://www.tpc.org)などで「公式」に認められているような性能測定を行う目的には向いていません。その点はご注意下さい。
pgbenchのインストール
pgbenchはPostgreSQLのソースが手元にあれば簡単にインストールできます。以後、本稿では最新安定版のPostgreSQL 8.4.3を前提に説明します。
pgbenchのインストールは、PostgreSQLのスーパユーザアカウント(通常"postgres")で以下を実行するだけです。
$ cd postgresql-8.4.3/contrib/pgbench $ make $ make install
Linux環境ではyumやaptなどのコマンドでバイナリパッケージをインストールするのが簡単です。たとえば、筆者の手元のLinux環境では、 postgresql-contribという名前のパッケージにpgbenchが含まれていました。
pgbenchのドキュメント
pgbenchのドキュメントは、PostgreSQLの付属ドキュメントに記述されています。「付録 F. 追加で提供されるモジュール」の「pgbench」 を参照してください。
pgbenchの仕組み
pgbenchはPostgreSQLのC言語インターフェイスであるlibpqを使用して実装されています。libpqには「非同期問い合わせ」という機能があり、問い合わせの結果を待たずに次の結果を送信することができます。こうしてpgbenchは一度に多数の問い合わせを扱うことによって、同時に多数のユーザがPostgreSQLを利用する環境をシミュレーションしています。
簡単なpgbenchの使い方
データベースを作る
可能であれば、pgbenchを利用する際には専用のデータベースを作っておくことをお勧めします。ここではこのデータベースを"test"とします。
ベンチマークデータを初期化する
pgbenchを使ってベンチマーク用のテーブル類を作成し、データをロードします。
$ pgbench -i test
ベンチマークを実行する
$ pgbench -c 10 -t 1000 test starting vacuum...end. transaction type: TPC-B (sort of) scaling factor: 1 query mode: simple number of clients: 10 number of transactions per client: 1000 number of transactions actually processed: 10000/10000 tps = 592.919181 (including connections establishing) tps = 594.661875 (excluding connections establishing)
ここで="-c 10"は、同時に10本の接続をPostgreSQLに張って、10人のユーザが利用する環境をシミュレーションすることを指定しています。"-t 1000"は、各接続あたり1000回のトランザクションを実行することを指定しています。
ベンチマーク結果の見方
scaling factor: 1
データサイズの規模を示す「スケーリングファクタ」が1、すなわち10万件のデータを使ってベンチマークしたことを示しています。
query mode: simple
psqlなどが利用している「普通の」方法を使って問い合わせを送信したことを示します。これ以外に、Javaなどで使用する「拡張プロトコル」を使って 問い合わせを送信することもできます。
number of clients: 10
-c 10を指定したので、同時接続ユーザ10で実行したことを示します。
number of transactions per client: 1000
-t 1000を指定したので、1クライアントあたり1000回トランザクションを実行したことを示します。ちなみに、-Tオプションを指定すると指定した秒数 間だけトランザクションを実行します。
number of transactions actually processed: 10000/10000
正常に実行されたトランザクションの割合を示します。今回は10*1000=10000回正常に実行できています。
tps = 592.919181 (including connections establishing) tps = 594.661875 (excluding connections establishing)
1秒間に実行できたトランザクションの数(Transactions Per Second = TPS)を表示しています。この数字が大きいほど性能が良いことになります。最初の数字は、PostgreSQLに対する接続を確立する時間を含んだTPSで、次は含まない数字です。当然後者の方が良い数字になっています。
pgbenchの実行するトランザクションとは
標準ではpgbenchは以下のような一連のSQLを一つのトランザクションとして実行します。
- pgbench_accountsを1件更新
- pgbench_accountsから1件検索
- pgbench_tellersを1件更新
- pgbench_branchesを1件更新
- pgbench_historyに1件行を追加
これは元々のTPC-Bが想定していた銀行の口座処理を模擬しているものです。
標準以外のトランザクション
pgbenchが標準で実行するトランザクションはTPC-Bを想定しているものとはいえ、実際に使ってみると不都合なこともあります。特に問題なのは、上記ステップ4で、pgbench_branchesの行数がスケーリングファクタと同じ(つまりデフォルトでは10)しかないため、同時接続数が10を超えるとロック競合が発生して性能が出なくなるということです。現実のシステムではこのような設計は普通は行わないので、実際のシステムでの性能を推し量るという、ベンチマーク本来の目的にはあまりそぐわないことになります。
そこでpgbenchでは3と4の処理を省略したトランザクションのモードを用意しており、pgbenchを実行するときに"-N"を付けることによって実行できます。Webシステムのように、多数の同時接続を想定している場合は、こちらを使うことをお勧めします。
この他、pgbenchでは、更新処理を行わない"-S"オプションもあるので、検索処理の性能だけを測定した場合はこちらを利用してください。
独自スクリプトの利用
実際のシステムでの性能を確かめるためには、できるだけ現実に即したトランザクションを実行することが必要です。そこでpgbenchでは、利用者が任意のSQLをトランザクションとして実行できる独自スクリプト機能が用意されています。
基本的には独自スクリプトは任意のSQL文の集まりで、たとえば以下のようなものになります。
BEGIN; SELECT CURRENT_TIMESTAMP; SELECT * FROM pg_class; END;
これをfoo.pgbenchのような名前のファイルに書いておき、
pgbench -f foo.pgbench
として指定することにより、標準のトランザクションの代りにfoo.pgbenchに書かれた一連のSQLが実行されるようになります。
当然のことながら、独自スクリプトを利用する場合は、アクセスされるテーブル類はすべて自前で用意しておく必要があります。
独自スクリプトで変数を利用する
独自スクリプトでは、変数を利用することもでき、工夫次第で現実のトランザクションに近づけることも可能です。例を示します。
\set foo 10 * :scale
ここで":scale"は、pgbench -s で指定したスケーリングファクタです。たとえば、pgbench -s 20 でpgbenchを起動すると、fooという変数には200が代入されます。
変数はSQL文の中から":"を付けて参照できます。
SELECT * FROM foobar WHERE i = :foo;
このほか、乱数を利用することもできます。
\setrandom foo 1 10 * :scale
これにより、fooには1から100までの値がランダムに代入されます(-s 10を指定した場合)。
変数の機能の詳細については、pgbenchのドキュメントをご覧下さい。
結果のグラフ化
pgbenchの実行結果は数値の羅列で見やすいものではありませんが、一手間かけるとグラフにして可視化できます。ここでは、簡単なシェルスクリプトと、グラフ描画ソフトのgnuplotを使った方法をご紹介します。
ここでは、同時接続数を1, 2... と倍々にして64まで増やしたときに、どのように検索性能が変化するのかをグラフにしてみましょう。まず、以下のスクリプトを実行します。
#! /bin/sh
for i in 1 2 4 8 16 32 64
do
echo -n "$i "
pgbench -p 5432 -n -S -T 60 -c $i test|grep "excluding"|awk '{print $3}'
done > bench.data
このスクリプトでは、検索トランザクションを(-S)毎回60秒間(-T 60)実行します。このスクリプトを実行すると、カレントディレクトリに"bench.data"というファイルができます。内容は、同時接続数とTPSがタブ区切りで1行に1セットという形式になっています。これを表計算ソフトなどで読み込んでグラフ化することもできますが、何度も実験を繰り返すと手間がかかるので、gnuplot用のスクリプトを書いて処理しましょう。
#! /bin/sh gnuplot <<EOF set ylabel "TPS" set key width 5 right box set title "SELECT ベンチマークテスト" plot 'bench.data' with linespoint lw 4 pt 1 ps 2 pause 1000 EOF
このスクリプトを"plot.sh"という名前で保存して実行すると、画面にグラフが表示されます。
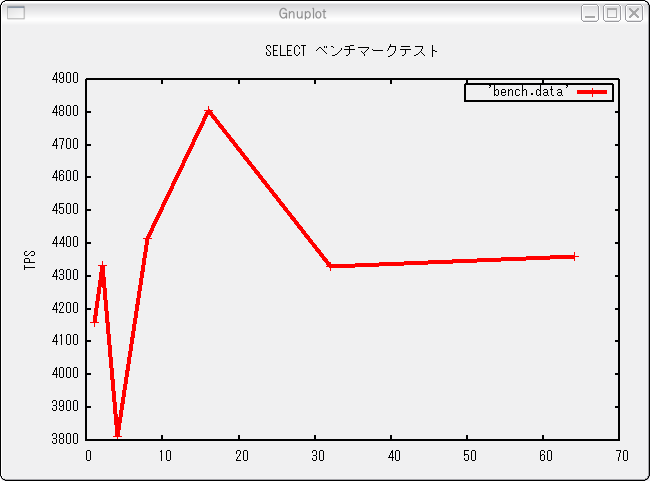
図1: pgbench結果のグラフ
レスポンスタイムの分布を知る
pgbenchが表示するTPS値は一定の期間の間に実行されたトランザクション数です。ここから、個々のトランザクションの平均応答時間を計算できます。しかし、実際には個々のトランザクションの応答時間にはばらつきがあり、時にはそのばらつき具合いを知りたいことがあります。この目的のためには、pgbenchの"- l"オプションが利用できます。
-l を指定してpgbenchを実行すると、カレントディレクトリに"pgbench_log.xxx"というファイルが出来ます。ここで"xxx"の部分はプロセスIDという数字で、たいていの場合は実行ごとに異なる数字になります。
たとえば、
pgbench -S -n -p 5432 -T 60 -l -c 1 test
を実行すると、pgbench_log.27083というファイルができて、以下のような内容になっています。
0 0 4433 0 1273412718 754410 0 1 573 0 1273412718 755063 0 2 546 0 1273412718 755625 0 3 530 0 1273412718 756171 : :
1行に1トランザクションのデータが記述されています。各行の数字は左から以下のようになります。
- クライアントID。0から始まり、pgbenchからPostgreSQLの接続に対応
- トランザクションID。0から始まり、各クライアントID内で実行した順に番号が振られます。
- マイクロ秒単位のトランザクション処理時間。
- スクリプトファイル番号。-fを指定したときだけ意味があります。
最後の2つの数字はトランザクションの終了時刻をマイクロ秒単位の精度で表します。最初の数字は1970年1月1日からの経過秒数、最後の数字はマイクロ秒です。
このデータを使って、横軸にpgbench開始からの経過時間、縦軸にトランザクション処理時間をプロットして、トランザクションの応答時間のばらつき具合いを視覚的に確認できるグラフを作ってみましょう。
まず、awkコマンドで前処理を行います。
awk '{print ($5-1273412718)+($6-754410)/1000000 " " $3/1000}'
pgbench_log.27083 > 1.data
この結果、1.dataには以下のようにpgbench開始からの相対時間(単位:秒)、トランザクション実行時間(単位:ミリ秒)のデータが書き込まれます。
0 4.433 0.000653 0.573 0.001215 0.546 0.001761 0.53 : : :
この結果を以下のスクリプトを使ってgnuplotでグラフ化すると、図のようになります。
gnuplot <<EOF set logscale y set ylabel "ミリ秒" set key width 5 right box set title "レスポンスタイム" plot '1.data' with points pause 1000 EOF
ご覧のように、この例ではほとんどのトランザクションは0.5ミリ秒程度の応答時間で実行できていますが、中には1秒近くかかっているものもあることが分かります。
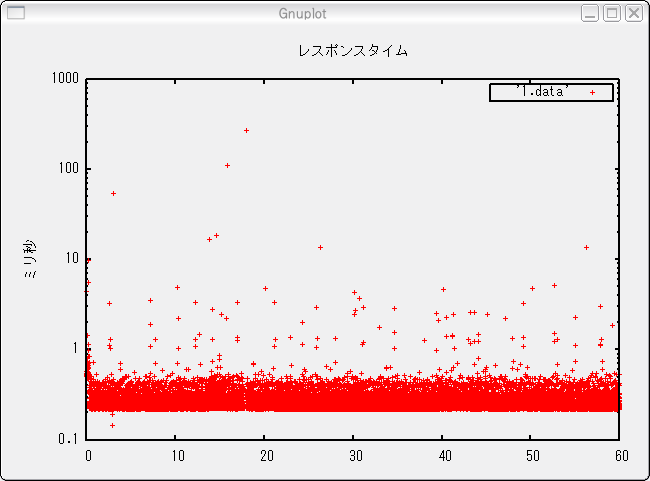
図2: レスポンスタイムのグラフ
\sleepの利用
ここまでご紹介した実行例では、トランザクションは次から次へと一瞬の休みもなしに実行されていましたが、これは実は現実世界とはだいぶ異なっています。たとえばWebアプリケーションでは、1ページ表示したらユーザはWeb画面を少し(時には随分長い間)眺めてから次の画面の表示を行います。そこでベンチマークの世界では、トランザクションとトランザクションの間に「考える時間」(コンピュータから見ると何もしない時間)を挿入することが多いのです。
pgbenchのスクリプトで使える\sleepという機能を使って、この「考える時間」を模擬的に実現できます。ここでは、pgbench -Sで実行されるトランザクションに\sleepを追加してみましょう。
以下のスクリプトをご覧下さい。上から3行まではpgbench -Sで実行されるトランザクションとまったく同じです。最後に\sleepを追加して1ミリ秒だけ「考える時間」を設けるようにしてみます。
\set naccounts 100000 * :scale \setrandom aid 1 :naccounts SELECT abalance FROM pgbench_accounts WHERE aid = :aid; \sleep 1 ms
これを-fオプションで指定してベンチマークを行った結果が図3のグラフです。ご覧のように、同時接続数の増加に応じてきれいにTPSが上がっていますし、TPSの最大値も以前の結果より良くなっています。
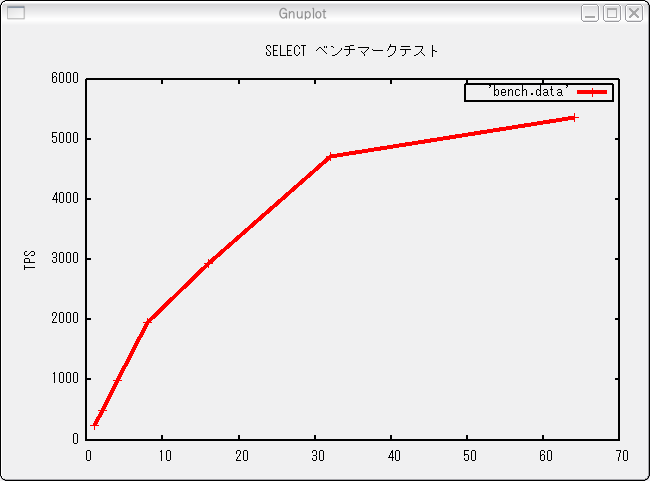
図3: \sleepを利用したグラフ
どうやら現実世界でのPostgreSQLの性能は、単純なpgbenchのデフォルトのベンチマークで推し量るよりも良い、と言えそうです。
なお、ここでは単純さのために\sleepで固定の1ミリ秒を指定していましたが、前述の\randomと組み合わせて「考える時間」をランダムにすることもできますし、実際のベンチマークではその方が好ましいでしょう。
注意事項
以上、簡単にpgbenchの使いかたとその応用を紹介しました。ここで、より適切というか、システムの実際の性能と掛け離れた数値をpgbenchで作り出さないための注意事項を説明します。
十分にpgbenchの実行時間を取る
「レスポンスタイムの分布を知る」のグラフを見ると分かりますが、短い時間の間では結構性能のばらつきがでます。これは平均値としての性能を知るためには問題となります。そこでpgbenchの実行時間は、十分長い時間を取ることをおすすめします。とりわけ、実行開始直後はOSやPostgreSQLのキャッシュの状態が定常状態になっていないため、実際よりも悪い数字になってしまう傾向があります。
また、pgbenchを繰り返し実行する場合、逆にキャッシュの影響で後になるほど良い結果が出てしまうことがあります。これもキャッシュが定常状態になっていれば防ぐことができます。
同時接続数の制限
pgbenchはそのアーキテクチャ上、同時接続数に上限があります。システムによって若干異なりますが、1000程度が上限です。それを超えてテストしたい場合は、複数のpgbenchを同時に実行してください。
pgbenchがボトルネックになっていないか確認する
高性能なサーバでは、PostgreSQLではなくてpgbench自体がボトルネックになって性能が出ないことがあります。その場合は、別の高性能なマシンでpgbenchを実行するなり、複数のマシンで同時にpgbenchを実行するなりしてください。
ちなみに、次期バージョンのPostgreSQL 9.0に付属するpgbenchはスレッドアーキテクチャで実行することもできるようになっており、pgbench自体の性能が向上しています。
一時的な性能低下の要因を把握する
今回は検索性能だけを測定したため問題になっていませんが、更新処理を含むトランザクションを実行すると、様々な要因で性能に影響が表われます。
ロック競合の影響
すでに説明したように、数少ない行を多数のトランザクションが更新しようとすると、ロック競合のために性能が低下します。これが元々システムの設計上想定済であればよいのですが、そうでない場合にはトランザクションを変えるなどの対策が必要です。
不要領域の増加
PostgreSQLでは、更新、削除の結果不要領域が作られます。これらはautovacuumで回収されるので通常は問題になりませんが、autovacuumが追い付かないほどの更新が発生すると著しく性能が低下します。システムの設計上これが折り込み済でない限りは、autovacuum関係のパラメータをチューニングするなどしてください。
チェックポイント関係のパラメータ
非常に更新負荷が高いトランザクションを実行すると、チェックポイントが頻発して性能が低下します。これも意図的なものでない限り、checkpoint_segmentsを適切に増やして回避しましょう。
最後に
pgbenchは誰でも簡単に利用できる性能測定ツールです。他のプログラムと組み合わせて性能を視覚的に確認することもできます。うまく活用して、PostgreSQLの性能を最大限に引き出しましょう。