
PostgreSQLを使ったチラシ・口コミサイトの構築・運営事例
オールクリエイター株式会社 橋本 俊秀
弊社の紹介と、今回のシステム「とっとくねっト」と弊社の関係
弊社、オールクリエイター株式会社 (http://allcreator.net) は、オープンソースCMSを使い、携帯サイト構築のお手伝いをするテクニカル・ディレクティング専門会社です。現在は、国立情報学研究所が次世代情報共有基盤システムとして開発した NetCommons を活用した携帯 & PC サイト構築、Web 業務システム開発に力をいれております。
弊社と「とっとくねっト」の関係
今回、事例紹介させていただいたシステムは、会員数2万人超の電子チラシサイト&口コミサイトで、サイト名は「とっとくねっト」といいます。http://www.tottoku.net (PC/携帯共通)
2003年夏ごろより、橋本 俊秀(筆者)がプロトタイプの開発に着手。2005年8月、アシストV株式会社様の ASP 事業として事業化、2006年1月実運用開始しました。同年春 Vodafone (現ソフトバンクモバイル)、au公式サイトとなり、電子チラシ市場の成長とともに、会員数 0 から着実に会員数を伸ばし、2008年秋には会員数2万人超、商品情報23万点、商品口コミ1万件のメガサイトへと成長しました。
2008年8月弊社(オールクリエイター株式会社)設立にともない、2008年11月7日、アシストV株式会社様より弊社に運営会社が切り替わり、現在に至っております。なお、携帯サイトとしては、現在ソフトバンクモバイル株式会社1社のみ公式サイトです。
PostgreSQLを利用したシステムとしての「とっとくねっト」
とっとくねっトの運用系のシステム構成は、図1のような感じです。業務システムでは比較的よくある構成だと思います。もちろん、システム障害などシビアなことを見だしたら、いくらでも見直しの余地はあると思いますが、そのあたりはインフラのシステムでもないので、予備機器を用意する程度で、割り切って構成しました。
ただ、インハウスで構築したので、共用や専用サーバ上に構築する場合より、かなり自由度をもって構築できました。また運用系以外にも、試験系システムと開発系システムを別途用意してプロジェクトを進めたので、そういった部分では小さいながらも本格的なものといってもいいかもしれません。
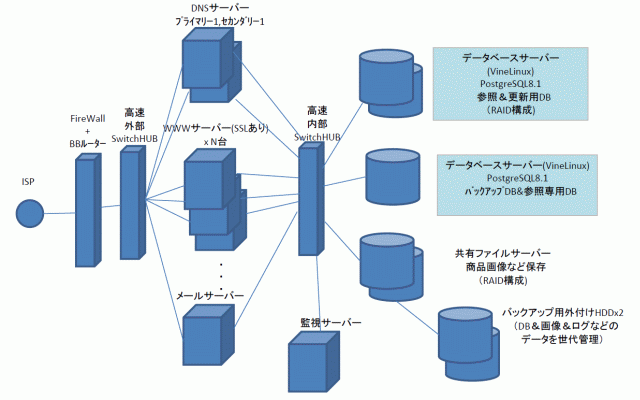
図1: とっとくねっト 構成図
PostgreSQL を採用した理由 ~(PostgreSQL にした、というより PostgreSQLになっていった経緯)
クライアントがいる場合のシステム開発におけるデータベース選択ならば、クライアントの要件や、環境面、性能要件、開発メンバの経験有無、そして費用などから使用するデータベースを選定する、というのがセオリーだと思います。
しかしながら、今回のシステムはクライアントがいるわけでなく、筆者がある日突然、「携帯3社に対応した電子チラシシステムを自分で作ってみようかな~」といった、ものすご~く単純な理由から作り始めたため、その決定経緯もきわめて特異、というか異例でした。
- まず最初に決めたのは、筆者はUNIXが大好きなので「サーバー OS は、Linux にする」です。
- 次に、サーバーサイド開発言語は、「コンパイル型言語よりスクリプト型言語が楽だし、サンプルソースやライブラリも多いから、実績のある Perl5 で行こう」でした。
そして、データベースを何にするか明確に決めないまま、システムのプロトタイプ開発に着手しました(筆者は、過去複数の DB ベンダーのデータベースを扱った経験があったので、正直、標準 SQL でつくるなら DB はなんでもいいや、ぐらいに思ってました)。
Perlのライブラリとしては、開発中に購入し、コーディングの参考にしていた本 (『Perl/CGI 逆引き大全 555 の極意』著者:津田貴史・萩原逸郎・伊藤智子・Web新撰組、出版社:秀和システム ISBN-13:978-4798002620)に使い方が手厚く載っていた、PostgreSQL 専用の DB 接続モジュール Pg を使いました。
実は、筆者はその昔、仕事の都合で Oracle と初期の PostgreSQL のパフォーマンス比較をしたことがありました。その時は結局 Oracle を採用したのですが、その比較結果から、「オープンソースの割に性能もそこそこだし、RDBMS として使える機能は一通り揃っているな~。チャンスがあったらいつか使ってみたいな。」と感想をもったことを思い出しました。なので、データベースは PostgreSQL で仮決定! ただ、まだちょっと不安があったので、いつでも他の DB に切り替えることができるよう、SQL 文はすべて標準 SQL でコーディングしました。
その後、開発を続けていく中で、サーバサイド言語は Perl5 から PHP4 へ、Linux ディストリビューションを RedHatLinux から VineLinux へと切り替えたのですが、データベースだけは PostgreSQL に対してなにも不満がなかった、というか開発を通して素晴らしいデータベースであると強く思うようになり、浮気せず使い続けることとなったのでした。
開発中の感想
エピソードその1
プログラム生産性の向上を考え、テーブル設計した際「連番型」「タイムスタンプの DB による内部取得」を採用しました。それによりコーディング量がぐっと減り、ラクさせてもらいました。
ところが、ある程度プログラムを作りこんだ後、データベースの二重化を検討し、そのツールとして pgpool を導入することにしました。一見、簡単に二重化できたように見えましたが、試験してみると、DB 2台の間で不整合がでることが判明。データベース自体にシリアル変数、タイムスタンプを内部取得させていたため、2台の DB サーバーがそれぞれ別のシリアル番号、微妙にずれた(ミリsecレベルのずれ)タイムスタンプを取るようになったためでした。そのため、pgpool がデータ突合した際、 warning を出すようになったのです。
よく調べてみると、pgpool の解説に、二重化に使う場合 (上記の問題があるので) Webサーバー側で採番、およびタイムスタンプ取得し SQL 文構築してから使う旨の記述を発見……。ですが、すでにこの時点で大量のプログラムを作っていたので、いまさら修正するわけもいかず、pgpool 導入を断念するはめになってしまいました。
最終的には、cron で定期的にマスター DB の内容をダンプし、それをバックアップ&参照 DB 側に登録する形で落ち着きました。参照 DB は主に、ブログバーツや、RESTapi からのアクセスを受け持つ参照専用 DB だったので、この程度の緩い同期で実質問題は発生しませんでした。
エピソードその2
標準 SQL に従った短い SQL 文の組み合わせでトランザクションを構成したので、分かりやすいソースにはなりました。あとで他のメンバーたちが開発に参加してきた際も、その点はいい方に働きました。
しかしながら実運用に入り、アクセス数が伸びてくるに従い、システムのレスポンスの遅さが大きな問題になってきました。別のメンバーが原因解析した結果、圧倒的に SQL 部分がボトルネックになっていることが判明したため、下記のような改造をすることにしました。
- 欲しい結果を1回の SQL 発行で済ませるよう JOIN を活用し、ソースを全面見直ししました。
- window 関数や PostgreSQL 独自の文法を使い、DB の力をなるべく引き出すソースに改造しました。
- 複雑な SQL、対象データの多い SQL を組み込む時は explain analyze select * from.... をつかって、コストをかならず把握してからコーディングするようにしました。
- カーソル関数はデータ件数が多い時オーバーヘッドが大きかったので、カーソル関数を避けるようにしました。
こういった改造によりレスポンスが劇的に向上し、その後、伸び続けるアクセスにも対応できるようになりました。正確な数値は現在手元にないのですが、データ件数が多い場合、30~40 倍かそれ以上のレスポンス向上があったと記憶しています。
運用時のエピソード
エピソードその1
運用に入ってから、オープンソースの決済系システムを導入して、連携させることにしました。が、それは、Perl, SJIS, TextDB というもので、簡単に移植できませんでた。
そこで、私たちは
- PostgreSQL のデータベースを、UNICODE で生成し直す。
- 既存系は EUC で、決済系は SJIS のまま使えるようにする。
- 既存系は、set_pg_client_encoding($conn, "EUC_JP") を利用。
- 決済系は、set_pg_client_encoding($conn, "SJIS") を利用。
- 決済の TextDB のテーブルと同等のものを create する。
- TextDB の文法が SQL ライクだったので、TextDB にアクセスする部分のインターフェイス・プログラムを書いて、実際には、PostgreSQL データベースへアクセスするよう改造。
- 既存のテーブルと、決済系テーブル群とのデータ連携には、PL/pgSQL を使いデータベーストリガーで実現させる。
ということを行いました。これにより、全く別々のものだった2システムを DB を通じて1つのものにすることができました。
但しそのあと、「開発言語、テーブル仕様が異なるため両方をセットで修正できるメンバーが限定される」「データベーストリガーは便利な反面、解析しずらい」などの問題点もでてくるようにはなりました。
エピソードその2
運用していく中で、PostgreSQL のメジャーバージョンが7.4から8.1に上がったので、私たちも移行を試みました。その際、一時期、8.1系の DB サーバー (更新系) と 7.4系の DB サーバー (参照系) が両方存在していたことがあり、それまでは 7.4系で binary バックアップをとっていたため、8.1系でのリストアに失敗する一幕がありました。
で、当然のことながら、参照系 DB もあわてて8.1系にあげ、事なきを得ました。今となってはいい思い出ですが、当時はとても焦りました。
このシステムに採用してよかったかどうか
今回のシステムに PostgreSQL を採用して大正解だったと思います。なぜなら、筆者含め開発メンバが過去経験してきたことが、ことごとく PostgreSQL を使った開発にピタッと当てはまったからです。また、コミュニティーが活発なこともあり、いろいろ有効な情報が入手しやすいのも魅力の1つでした。
今後の予定
弊社は、現在、国立情報学研究所(NII)が開発したオープンソースのコミュニティウェア「NetCommons」を使ったWeb・携帯システムの構築をやっております。この NetCommons(ネットコモンズ)は、
- 外部配信向けのポータルサイト/グループの情報共有ソフトウェア/個人のデスクトップ、の3つの異なる空間を1つのシステムで有機的に統合できる。
- 厳選されたモジュール群(カレンダ、日誌、掲示板、予約、小テスト、キャビネットなど)の組み合わせ方次第で、eラーニングシステム/グループウエア/SNS/文書管理システムなど、性質の異なるシステムに仕上げることができる。
- 表示したい場所をダブルクリックするだけで WYSIWIG エディタを使い、「直接」「その場所」でコンテンツ更新でき、かつその配置をドラッグ&ドロップで簡単に変更できる。
- コンテンツの更新・閲覧の権限を、人単位・グループ単位で細かくコントロールできる。
- PC Web、携帯 Web の両方から、コンテンツの閲覧・更新ができる。
といった特徴をもっているソフトウェアです。残念ながら、現時点では、データベースとして MySQL しか使えないのですが、弊社は NetCommons を PostgreSQL でも使えるように改良していきたいと思っております。
関連リンク
(2009年6月30日 公開)