
pgpool-II 3.3 の watchdog 機能
SRA OSS, Inc. 日本支社
長田 悠吾
はじめに
2013 年 8 月に pgpool-II 3.3 がリリースされました。このバージョンでは、複数の pgpool-II を連携させ、可用性を高める機能である watchdog 関して、いくつか新機能が追加されました。 中でも大きな変更は、pgpool-II 間の死活監視に新しい方法が追加されたことです。 本記事では、この新しい監視方法を用いた pgpool-II 3.3 の watchdog 機能について解説します。
pgpool-II および watchdog について
pgpool-II とは
pgpool-II は、PostgreSQL のクライアントアプリケーションと、(複数の)PostgreSQL の間に割り込んで入る proxy のような形で利用するミドルウェアです。直接 PostgreSQL を使うのではなく、pgpool-II を経由することによって、コネクションプーリング、負荷分散、自動フェイルオーバ、レプリケーション、オンメモリクエリキャッシュなど、 様々な機能が利用できるようになります。
pgpool-II は公式サイトよりダウンロード可能です。 機能の詳細については pgpool-II の公式ドキュメントやチュートリアル、そして Let's Postgres の pgpool-II 関連記事(pgpool-II を使用した様々なクラスタ構成の紹介、 pgpool-II 3.2 の新機能)を参照ください。
watchdog とは
watchdog は pgpool-II 3.2 から追加された機能の1つで、複数の pgpool-II を連携させることにより、その可用性を高める機能です。 それより前のバージョンでは、複数の PostgreSQL を連携させる高可用性は実現していましたが、pgpool-II 自体、あるいは pgpool-II が動いているサーバや OS に障害が発生すると全体のサービスが停止してしまうため、ここが単一障害点(Single Point of Failure: SPoF)となっていました。しかし、watchdog 機能は複数の pgpool-II を連携させることで問題を解決し pgpool-II 自体の可用性を高めることができます。具体的には、サービスを提供する主系(アクティブ)の pgpool-II に障害が発生した場合に、それを検知した待機系(スタンバイ)の pgpool-II が主系に取って代わって運用を継続する、すなわち pgpool-II のフェイルオーバが実現可能です。
以前はこのような構成をとるためには pgpool-HA というパッケージが別に必要でしたが、pgpool-II 3.2 以降では pgoool-II 自身がこの機能を持つようになりました。また、複数の pgpool-II を同時に利用するいわゆる「マルチマスタ」的な使い方も可能であり、この構成についても 後で説明 します。
pgpool-II 3.3 の watchdog について
バージョン 3.3 からは watchdog に関する新機能がいくつか追加されました。大きな変更は新しい死活監視方法の追加です(次章参照)。 本記事ではこの新しい機能を用いて watchdog の解説を行います。従来の死活監視法を用いた watchdog の解説は「 pgpool-II 3.2 の新機能 (3) Watchdog」を参照してください。
pgpool-II 3.3 の watchdog の主な新機能は以下の通りです。
- ハートビート信号を用いた新しい死活監視方法が追加されました。(詳細)
- フェールオーバ/フェールバックコマンドが pgpool-II 間で排他的に実行されるようになりました。(詳細)
- watchdog 間通信に認証機能が追加されました。(詳細)
- 仮想 IP を用いない構成が可能になりました。(詳細)
- watchdog ステータスを取得する pcp_watchdog_info コマンドが追加されました。(詳細)
- アクティブ/スタンバイの切り替え時に、共有メモリ上のクエリキャッシュがクリアされるようになりました。(詳細)
- アクティブ/スタンバイの切り替え時に、任意のコマンドを実行できるようになりました。(詳細)
これらの新機能の詳細については本記事のなかで解説します。
1. watchdog の概要
watchdog は以下の機能を提供します。
1.1. pgpool-II の死活監視
watchdog は pgpool-II の死活監視を行います。監視の方法は「ハートビート」モードと「クエリ」モードの2つがあります。 「ハートビート」モードはバージョン 3.3 から追加された新しい監視方法です。
ハートビートモードでは、watchdog はハートビート信号を用いて 他の pgpool-II プロセスの死活監視を行います。 watchdog は定期的にハートビート信号を他の pgpool-II に向けて送信します。また、他の pgpool-II からの ハートビート信号を受信し、これが一定期間以上途切れた場合には当該 pgpool-II プロセスに障害が発生した(ダウンした)と判断します。 冗長性を高めるために、複数のネットワークを用いたハートビート交換が可能です。 デフォルトではこのモードで動作し、これが推奨設定です。
クエリモードでは、watchdog は pgpool-II のプロセスではなく「サービス」の応答を監視します。 このモードでは、監視対象の pgpool-II にクエリ(デフォルトでは "SELECT 1")を発行しその応答をチェックすることで、その pgpool-II がサービスを提供可能かどうかを判断します。 この方法では他の pgpool-II から接続を受ける必要があるため、num_init_children が十分大きくない場合には監視が失敗する場合があることに注意してください。 これは非推奨の監視方法であり、下位互換のために残されています。
また watchdog は、pgpool-II から上位のサーバ(アプリケーションサーバなど)への接続も監視します。具体的には、上位サーバへ発信した ping の応答が無い場合には、その pgpool-II は上位サーバへサービスを提供できない状態(ダウン状態)であると判断されます。
1.2. pgpool-II 間の協調動作
watchdog は互いに情報交換を行うことで複数の pgpool-II を協調動作させます。
フェイルオーバなどでバックエンドノードの状態が変化した場合には、この情報を他の pgpool-II へ伝達し、同期を行います。 オンラインリカバリ時には、複数の pgpool-II で DB に不整合が生じないよう他の pgpool-II へのクライアントの接続を制限します。
また、フェイルオーバ、ファイルバックの際に実行されるコマンド( failover_command, failback_command, follow_master_command )は、インターロック機構により、1つの pgpool-II でのみ実行されます。 このインターロック機構はバージョン 3.3 からの新機能です。従来は、これらのコマンドは全ての pgpool-II で実行されていました。
1.3. 障害発生検知時のアクティブ/スタンバイ切り替え
pgpool-II プロセスやそれが動いているサーバ OS、ネットワークの障害による pgpool-II のダウン状態は watchdog の相互監視により検出されます。また、自分自身の pgpool-II がダウンした場合、watchdog は他の watchdog へそれを通知します。アクティブな pgpool-II がダウンした場合、他の watchdog は新しいアクティブを投票で決め、アクティブ/スタンバイの切り替えを行います。
1.4. 仮想 IP アドレスの自動付け替え
アクティブな pgpool-II は仮想 IP で接続を受け付けます。スタンバイ pgpool-II が新しいアクティブに昇格する時に、新アクティブ機の watchdog は仮想 IP インターフェースを立ち上げます。 一方、旧アクティブ機の watchdog は仮想 IP インターフェースを停止します。これにより、サーバが切り替わった後も新アクティブ機は同じ IP アドレスを使ってサービスを継続します。
1.5. スタンバイ機としての自動登録
サーバの起動時に watchdog は自分自身のサーバ情報を他の watchdog に通知し、その応答として他の watchdog のサーバの情報を受け取ります。それに伴い、サーバはスタンバイ機として自動的にクラスタに追加されます。
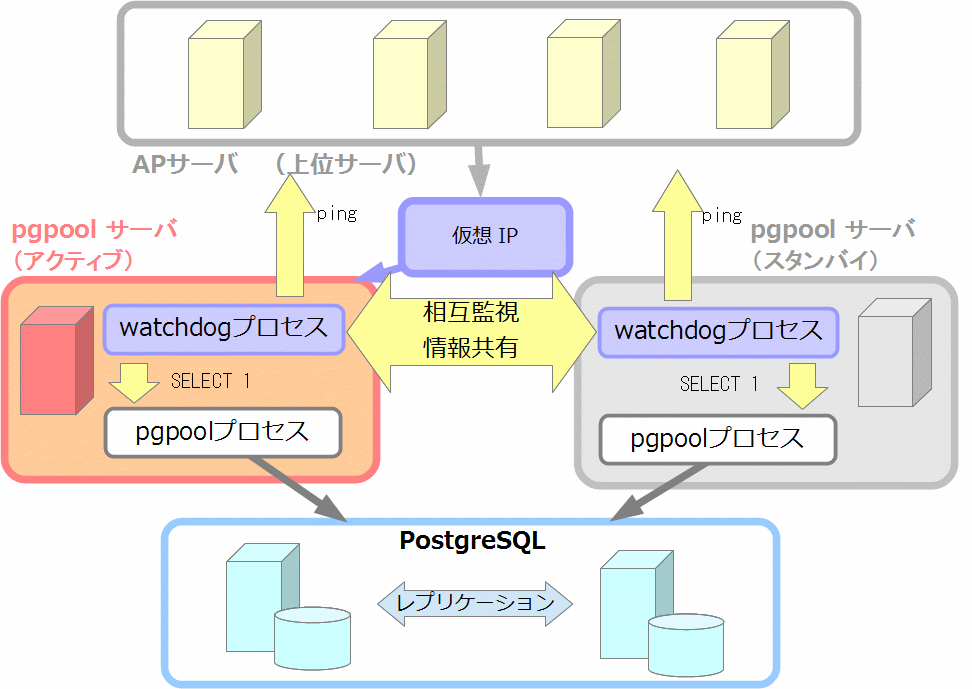
2. 全体構成
watchdog プロセスを含む pgpool-II サーバは以下の図のようなシステム構成をとります。(pgpool-II が2台の場合、ハートビートモードでの例です)
3. 設定方法
クラスタを構成する全ての pgpool-II で pgpool.conf の設定を行う必要があります。ここでは2台の pgpool-II を2台のサーバ(server1, server2)で動かす場合を例に説明します。死活監視の方法は「ハートビート」モードを用います。また、バックエンドの PostgreSQL は pgpool-II とは別のサーバで動いていると仮定しています。
まず、watchdog 機能を有効にするフラグ use_watchdog を on にします。
use_watchdog = on
# Activates watchdog
3.1. 上位サーバ
pgpool-II のサービス提供先のサーバ(AP サーバなどのクライアント)を上位サーバと呼びます。 pgpool-II のプロセスが生きていても、ネットワーク障害などで上位サーバへのサービスが提供不能な場合があります。この状態を pgpool-II の障害発生として検出するために、watchdog は上位サーバとのリンクを監視します。
上位のサーバのリストは trusted_servers に指定します。複数のホスト名または IP アドレスをカンマ区切りで指定できます。空欄あるいは指定なしの場合には上位サーバへの接続監視は行いません。ここでは空欄にしておきます。
trusted_servers = ''
# trusted server list which are used
# to confirm network connection
# (hostA,hostB,hostC,...)
なお、上位サーバへの接続監視は、trusted_servers に指定したサーバ群に対して、ping を実行することで行われます。どのサーバからも応答が帰ってこなかった場合、watchdog は自身の pgpool-II に障害が発生した(ダウンした)と見なします。
ping コマンドのパスは ping_path パラメータで指定できます。
ping_path = '/bin'
# ping command path
通常はデフォルトのままで問題ありません。
3.2. 仮想 IP
アクティブ機が立ち上げる仮想 IP を delegate_IP に指定します。まだ他のノードで使われてない IP アドレスを記述します。またクラスタを構成する pgpool-II で共通の IP アドレスを指定してください。
すでに使用済みの IP アドレスが指定された場合、及び、pgpool-II 間で異なる IP アドレスが指定された場合には pgpool-II は起動しません。ここでは以下のように設定します。
delegate_IP = '133.137.177.222'
# delegate IP address
マルチマスタ構成などで仮想 IP を使用しない場合には空欄にしておくこともできます。その場合には、仮想 IP の立ち上げ、切り替えは実行されません。これはバージョン 3.3 からの新機能であり、以前はこのパラメータが空の場合には起動時にエラーとなっていました。
3.3. watchdog サーバ
watchdog が他の watchdog から情報を受け取るためのホスト名または IP アドレスを wd_hostname、ポート番号を wd_port に指定します。
wd_hostname は watchdog 識別の為の ID としても用いられます。省略した場合には hostname コマンドの結果が使われますが、出来る限り明示的に指定することをお勧めします。ここではそれぞれ server1, server2 を指定します。wd_port はデフォルト値の 9000 にしておきます。
- server1
wd_hostname = 'server1' # Host name or IP address of this watchdog wd_port = 9000 # port number for watchdog service - server2
wd_hostname = 'server2' # Host name or IP address of this watchdog wd_port = 9000 # port number for watchdog service
3.4. 認証キー
wd_authkey には wachdog 間通信で用いられる認証キーを指定します。これは全ての pgpool-II で同じキーを指定する必要があります。 認証キーが異なる watchdog からの通信は全て拒絶されます。これはバージョン 3.3 からの新機能です。 デフォルトでは空欄となっており認証は行われません。ここでは空欄にしておきます。
wd_authkey = ''
# Authentication key for watchdog communication
3.5. 監視対象サーバ関連
監視対象の pgpool-II が稼働するホスト名を other_pgpool_hostname0 に、その pgpool-II のポート番号を other_pgpool_port0 に、その watchdog のポート番号 other_wd_port0 にそれぞれで記述します。 監視対象を複数指定する場合は、other_pgpool_hostname1, other_pgpool_port1, other_wd_port1 といった感じに数字部分を連番にして続けます。
ここでは自分以外の pgpool-II は1台だけなので、0 番目のオプションのみ指定します。
- server1
other_pgpool_hostname0 = 'server2' # Host name or IP address to connect to for other pgpool 0 other_pgpool_port0 = 9999 # Port number for othet pgpool 0 other_wd_port0 = 9000 # Port number for othet watchdog 0 - server2
other_pgpool_hostname0 = 'server1' # Host name or IP address to connect to for other pgpool 0 other_pgpool_port0 = 9999 # Port number for othet pgpool 0 other_wd_port0 = 9000 # Port number for othet watchdog 0
3.6. ハートビート送信先
ハートビート信号の送信先のホスト名または IP アドレスを heartbeat_destination0 に、ハートビート受信用のポート番号を heartbeat_destination_port0 に指定します。 監視ネットワーク(インターコネクト)の冗長性を高めるため 1 台の pgpool-II に対して複数の送信先をすることが可能ですが、ここでは 1 つの送信先(other_pgpool_hostname0 と同じもの)を指定します。ポート番号はデフォルトの 9694 を用います。
heartbeat_device0 にはハートビート信号の送受信に用いる NIC デバイス名を指定可能です。指定されたデバイスがハートビート送受信用のポートにバインドされます。空欄の場合にはバインドは行われません。 なお、この機能は pgpool-II が root 権限で実行されているときにのみ有効です。それ以外の場合にはこのパラメータは無視され、バインドは行われません。
- server1
heartbeat_destination0 = 'server2' # Host name or IP address of destination 0 # for sending heartbeat signal. # (change requires restart) heartbeat_destination_port0 = 9694 # Port number of destination 0 for sending # heartbeat signal. Usually this is the # same as wd_heartbeat_port. # (change requires restart) heartbeat_device0 = '' # Name of NIC device using for # sending/receiving heartbeat signal # to/from destination 0. # This works only when pgpool has root privilege. # (change requires restart) - server2
heartbeat_destination0 = 'server1' # Host name or IP address of destination 0 # for sending heartbeat signal. # (change requires restart) heartbeat_destination_port0 = 9694 # Port number of destination 0 for sending # heartbeat signal. Usually this is the # same as wd_heartbeat_port. # (change requires restart) heartbeat_device0 = '' # Name of NIC device using for # sending/receiving heartbeat signal # to/from destination 0. # This works only when pgpool has root privilege. # (change requires restart)
4. 使用方法
以降は、実際に watchdog を動かしその機能を確認していきます。クエリの実行の様子をログで確認するために log_statement オプションを on にしておきます。
log_statement = on
# Log all statements
4.1. watchdog プロセスの起動
4.1.1. アクティブ pgpool-II の起動
watchdog は pgpool-II を起動すると、自動的にその子プロセスとして起動されます。ただし、watchdog 使用時は仮想 IP インタフェースの起動・停止を行うため、pgopol-II の起動は root 権限で行う必要があります*1)。
起動した pgpool-II がアクティブ/スタンバイのどちらになるかは起動順で決まります。一番最初に起動した pgpool-II がアクティブ、それ以降に起動した pgpool-II はスタンバイとなります。ここでは server1 の pgpool-II を先に起動します。
(server1) $ sudo bin/pgpool -n >pgpool.log 2>&1
server1のログに以下のメッセージが出力されます。
LOG: pid 30482: wd_create_send_socket: connect() reports failure (Connection refused).
You can safely ignore this while starting up.
LOG: pid 30482: send_packet_4_nodes: packet for 133.137.177.146:9000 is canceled
LOG: pid 30482: wd_escalation: escalating to master pgpool
LOG: pid 30482: wd_escalation: escaleted to master pgpool successfully
LOG: pid 30482: wd_init: start watchdog
LOG: pid 30482: pgpool-II successfully started. version 3.3.0 (tokakiboshi)
LOG: pid 30482: find_primary_node: primary node id is 1
これから、server1 がアクティブ(ログ中では master と出力されています)として起動したこと、 pgpool-II, watchdog 共に正しく起動していることがわかります。1行目に Connection refused と出力されているのは、監視対象である server2 の pgpool-II がまだ起動していないためであり、ここでは無視してかまいません。
watchdog は上位サーバへの接続、及び、監視対象の pgpool-II の起動を待ってから死活監視を開始します。 この段階では server2 の pgpool-II が起動していないので死活監視はまだ始まっていません。
4.1.2. スタンバイ pgpool-II の起動:死活監視開始
次に server2 の pgpool-II を起動します。
(server2) $ sudo bin/pgpool -n >pgpool.log 2>&1
以下のようなログが出力されます。
LOG: pid 7145: wd_init: start watchdog LOG: pid 7145: pgpool-II successfully started. version 3.2.3 (tokakiboshi) LOG: pid 7145: find_primary_node: primary node id is 1 ・・・ LOG: pid 7148: watchdog: lifecheck started
watchdog, pgpool-II が正常に起動し、死活監視(lifecheck)が開始されたことがわかります。 server1 のログにも server2 の開始受付と死活監視開始のメッセージが出力されます。
LOG: pid 30488: wd_send_response: receive add request from server2:9999 and accept it LOG: pid 30488: watchdog: lifecheck started
4.1.3. 死活監視が始まらないとき
watchdog が正しく働いてないように見える場合には、ログを確認して死活監視が始まっているかどうかをチェックしてください。
死活監視が始まらない場合は、ホスト名やポート番号の指定は正しいか、サーバ間のネットワークに問題はないか、ファイアウォールが邪魔をしていないか等を確認してみてください。
4.2. watchdog 起動時のエラー
下記の場合にはエラーとなり、pgpool-II は起動せずに終了してしまいます。
- 起動時に上位サーバに接続できない場合
-
以下のメッセージを出力して終了します。
ERROR: pid 25194: wd_init: failed to connect trusted server ERROR: pid 25194: watchdog: wd_init failed ERROR: pid 25194: wd_main error
- delegate_IP に既存の IP が指定されている場合
-
以下のメッセージを出力して終了します。
ERROR: pid 25203: wd_init: delegate_IP xxx.xxx.xxx.xxx already exists ERROR: pid 25203: watchdog: wd_init failed ERROR: pid 25203: wd_main error
- pgpool-II 間で仮想 IP の指定が異なる場合
-
2台目以降に起動した pgpool-II の
delegate_IPが最初に起動した pgpool-II のdelegate_IPと異なる場合、後から起動した pgpool-II は以下のメッセージを出力して終了します。ERROR: pid 15406: wd_init: failed to start watchdog ERROR: pid 15406: watchdog: wd_init failed ERROR: pid 15406: wd_main error
また、最初に起動した pgpool-II のログには以下のメッセージが出力されます。
ERROR: pid 25261: wd_set_wd_list: delegate IP mismatch error LOG: pid 30488: wd_send_response: receive add request from server2:9999 and reject it
- 設定ファイルの不備
-
監視対象 pgpool-II の指定がされていない場合、以下のメッセージを出力して終了します。
ERROR: pid 15458: wd_check_config: there is no other pgpools setting. ERROR: pid 15458: watchdog: wd_check_config failed ERROR: pid 15458: wd_main error
4.3. 接続の確認
server1 で ifconfig コマンドを実行して、delegate_IP で指定した仮想 IP が立ち上がっていることを確認します。
(server1) $ /sbin/ifconfig eth0 ・・・ ・・・ eth0:0 Link encap:Ethernet HWaddr 00:1E:C9:xx:xx:xx inet addr:133.137.177.222 Bcast:133.137.177.255 Mask:255.255.255.0 ・・・
また、psql で仮想 IP に接続し、アクティブである server1 の pgpool-II でクエリが実行されることを確認します。
$ psql -h 133.137.177.222 -p 9999 -U postgres -c “SELECT 'test query'”
server1 のログに以下のように出力されます。
LOG: pid 30959: statement: SELECT 'test query'
4.4. watchdog の停止とアクティブ/スタンバイの切り替え
pgpool-II を停止すると watchdog も停止します。watchdog は停止する直前に「自分がダウンすること」を他の pgpool-II へ通知します。また、アクティブの場合には仮想 IP インタフェースを停止させます。
Ctrl-C で server1 の pgpool-II を停止させます。すると server1 では以下のログが出力されます。
LOG: pid 30482: received fast shutdown request LOG: pid 30488: wd_IP_down: ifconfig down succeeded
server1 からダウン通知を受け取った server2 はスタンバイからアクティブに昇格します。 server2 には以下のログが出力されます。
LOG: pid 7147: wd_escalation: escalating to master pgpool LOG: pid 7147: wd_escalation: escaleted to master pgpool successfully LOG: pid 7147: check_pgpool_status_by_hb: pgpool 1 (osspc19:9999) is in down status LOG: pid 7147: check_pgpool_status_by_hb: pgpool 1 (osspc19:9999) is in down status ・・・
psql で仮想 IP に接続すると、クエリは server2 で実行されることを確認します。
$ psql -h 133.137.177.222 -p 9999 -U postgres -c “SELECT 'test query'”
server2 のログに以下のように出力されます。
LOG: pid 8189: statement: SELECT 'test query'
4.5. pgpool-II の再起動
先ほど停止させた server1 の pgpool-II を再度スタンバイとして起動させます。
(server2) $ sudo bin/pgpool -n >pgpool.log 2>&1
server1 のログには以下が出力され、死活監視が再び開始されたことが確認できます。
LOG: pid 31442: wd_init: start watchdog LOG: pid 31442: pgpool-II successfully started. version 3.3.0 (tokakiboshi) LOG: pid 31442: find_primary_node: primary node id is 1 ・・・ LOG: pid 31445: watchdog: lifecheck started
server2 のログには以下が出力され、server1 の起動を受け付けたことが確認できます。
LOG: pid 7147: wd_send_response: receive add request from server1:9999 and accept it
4.6. ネットワーク遮断
先ほどは pgpool-II を停止した場合のアクティブ/スタンバイの切り替わりを確認しました。今度はネットワーク障害が発生した場合に、アクティブ/スタンバイが切り替わることを実験してみます。
現在スタンバイである server1 とアクティブである server2 の間の接続が遮断された状況をシミュレートするため、各サーバの /etc/hosts を以下のように編集して、相手のサーバホスト名に無効な IP アドレスを対応付けます。
(server1) $ sudo vi /etc/hosts # 133.137.177.220 はノードに対応付けられていない無効なIPアドレス 133.137.177.220 server2
(server2) $ sudo vi /etc/hosts # 133.137.177.210 はノードに対応付けられていない無効なIPアドレス 133.137.177.210 server1
こうすると互いのホスト名の名前解決が正しく出来なくなりハートビート信号の送受信ができなくなります。 /etc/hosts の書き換えからしばらくすると server1 の pgpool-II は server2 の pgpool-II がダウンしていると判断し、新アクティブに昇格しようとします。 server1 のログに以下のメッセージが出力され、pgpool-II がアクティブに昇格したことが確認できます *2)。
LOG: pid 31142: check_pgpool_status_by_hb: lifecheck failed. pgpool 1 (server2:9999) seems not to be working LOG: pid 31142: pgpool_down: server2:9999 is going down LOG: pid 31142: pgpool_down: I'm oldest so standing for master LOG: pid 31142: wd_escalation: escalatting to master pgpool LOG: pid 31142: wd_escalation: escalated to master pgpool successfully LOG: pid 31142: check_pgpool_status_by_hb: pgpool 1 (server2:9999) is in down status LOG: pid 31142: check_pgpool_status_by_hb: pgpool 1 (server2:9999) is in down status ・・・
5. 内部構造
以降は watchdog の動作について詳細に説明します。
5.1. 死活監視
ハートビートモードでの死活監視の振る舞いは以下のパラメータで指定できます。
wd_interval = 10
# lifecheck interval (sec) > 0
# -- heartbeat mode --
wd_heartbeat_keepalive = 2
# Interval time of sending heartbeat signal (sec)
# (change requires restart)
wd_heartbeat_deadtime = 30
# Deadtime interval for heartbeat signal (sec)
# (change requires restart)
wd_interval は死活監視を行う間隔(秒)を指定します。具体的にハートビートモードでは「監視対象の pgpool-II からハートビート信号が届いているかどうか」のチェックが行われます。 (クエリモードでは、wd_interval 秒に 1回、監視対象の pgpool-II に指定クエリを発行しその応答をチェックします。)
ハートビート信号は wd_heatbeat_keepalive 秒毎に、heartbeat_destination, heatbeat_destination_port で指定された宛先へ発信されます。 なお、ハートビート信号のプロトコルには UDP が使われています。 ハートビート信号の受信情況は wd_interval 秒毎にチェックされ、 wd_heatbeat_deadtime 秒以上信号が途絶えた pgpool-II は、障害が発生した(ダウンした)と見なされます。
また、この死活監視が行われるタイミングで、上位サーバへの接続もチェックされます。 trusted_servers に指定したサーバ群に対して ping を実行し、どのサーバからも応答が帰ってこなかった場合、watchdog は自身の pgpool-II がダウンしたものと見なします。
5.2. アクティブ/スタンバイの切り替え
5.2.1. 死活監視の結果に基づく動作
死活監視の結果に基づき watchdog は以下のように振舞います。
- 自分自身がダウンした場合
- そのことを他の pgpool-IIに通知します。
- 自分以外のアクティブな pgpool-II がダウンした場合
- 起動したのが一番古い最古参の pgpool-II が新しい アクティブ に立候補します。もし他にアクティブな pgpool-II がいない場合、立候補した pgpool-II が新しいアクティブに昇格します。
- 自分がダウン状態から復帰したとき
- そのことを他の pgpool-II に通知します。もし他にアクティブな pgpool-II がいない場合には新しいアクティブに昇格します。
5.2.2. 他の pgpool-II からの通知に基づく動作
以下は、他の pgpool-II からの通知を受けてアクティブ/スタンバイを切り替えるケースです。
- 他の pgpool-II のダウン通知を受信した場合
- 自分が最古参の場合にはアクティブに昇格します。
- 他の pgpool-II がアクティブに昇格した場合
- 自分がアクティブであった場合にはスタンバイに降格します。そうすることで、アクティブが複数になることを回避します*3)。
5.2.3. pgpool-II ステータスの確認
pgpool-II がアクティブか、スタンバイか、ダウンかといったステータスは、以下の pcp_watchdog_info コマンドを用いて確認することができます。
書式 pcp_watchdog_info _timeout_ _host_ _port_ _userid_ _passwd_ [_watchdog_id_]
このコマンドは、pgpool.conf の watchdog セクションで定義された pgpool-II の watchdog ステータスを表示します。 _timeout_, _host_, _port_, _userid_, _passwd_ は全ての PCP コマンドの共通引数で、それぞれタイムアウト、pgpool-II のホスト、 PCP コマンドのポート番号(デフォルト 9898)、ユーザID、パスワードを指定します。 _watchdog_id_ には other_pgpool_hostname パラメータの添字を指定します。 _watchdog_id_ が省略された場合には、_host_:_port_ で動作している pgpool-II の watchdog ステータスが表示されます。
出力結果は以下の例のとおりです。
$ pcp_watchdog_info 0 server1 9898 postgres hogehoge server1 9999 9000 2 $ pcp_watchdog_info 0 server1 9898 postgres hogehoge 0 server2 9999 9000 3
結果は順に、pgpool-II のホスト名、pgpool-II ポート番号、watchdog ポート番号、watchdog ステータスを表しています。また、ステータスは、1: 初期状態(指定された pgpool-II が未起動の場合に表示される)、2: スタンバイ、3: アクティブ、4: ダウン、を表します。すなわち、以上の出力結果は
| 自分自身(server1 で動作中)の pgpool-II | server1 の other_pgpool_hostname0 に指定した pgpool-II | |
|---|---|---|
| ホスト名 | server1 | server2 |
| pgpool- II ポート番号 | 9999 | 9999 |
| watchdog ポート番号 | 9000 | 9000 |
| ステータス | スタンバイ(2) | アクティブ(3) |
であることを意味します。この pcp_watchdog_info コマンドはバージョン 3.3 からの新機能です。
5.2.4. pgpoolAdmin による watchdog 情報の表示
pgpool-II 3.3.0 のリリースと同時に、pgpoolAdmin 3.3.0 がリリースされました。pgpoolAdmin は pgpool-II の管理操作(開始・終了、フェイルオーバ・フェイルバックなど)を GUI から行える Web アプリです。 こちらよりダウンロードすることができます。
pgpoolAdmin 3.3.0 からは、pgpool-II の watchdog ステータスや、仮想 IP など、watchdog に関する情報を GUI 画面から確認できるようになりました。内部では前節で解説した pcp_watchdog_info コマンドを使用しています。

5.2.5. クエリキャッシュのクリア
pgpool-II 3.2 以降にはオンメモリクエリキャッシュという、参照クエリの結果をメモリ上にキャッシュすることにより参照性能を高める機能があります。 この機能の使用時にアクティブ/スタンバイの切り替えが起こり、クライアントがアクセスする pgpool-II が切り替わった時に、新アクティブに旧アクティブと非整合なクエリキャッシュが残っていては、pgpool-II は間違った結果をクライアントに返してしまう可能性があります。 これを防止するため、バージョン 3.3 からはデフォルトで、pgpool-II がアクティブに昇格した時に、共有メモリ上のクエリキャッシュを全て削除するようになりました。
この機能を無効にしたい場合は、 clear_memqcache_on_escalation パラメータに off を設定します。なお、この機能は共有メモリ使用時( memqcache_method が 'shmem'の場合)にのみ有効です。
5.2.6. コマンドの実行
pgpool-II がアクティブに昇格した時に、 wd_escalation_command に指定した任意のコマンドを実行することができます。このコマンドは、仮想 IP が立ち上がる直前のタイミングで実行されます。 このタイミングで任意のメッセージをログ出力したり、管理者にメールで通知を行うなどが可能です。 これは、バージョン 3.3 からの新機能です。
5.3 情報共有の詳細
5.3.1. サーバ情報の共有
watchdog は自分を含む監視対象サーバの情報を保持しており、それを互いに交換・共有しています。個々のサーバ情報は具体的には以下の通りです。
- ホスト名
- pgpool のポート番号
- watchdog のポート番号
- ステータス(アクティブ / スタンバイ / ダウン など)
- 仮想 IP の情報
- 起動時刻
watchdog は起動時に、他の監視対象のサーバ情報をまとめて受け取ります。また、起動時や停止時、アクティブへの昇格時など、他の watchdog と通信する際にもサーバ情報の送受信が行われます。
5.3.2. DB ノード状態の共有
複数の pgpool-II で複数の PostgreSQL を共有している場合、pgpool-II 間で DBノードの状態が共有されている必要があります。例えば、1つの pgpool-II である DB を切り離した場合、他の pgpool-II でも同じ DB を切り離しておかなければ DB 間で一貫性が失われる恐れがあります。
このため、watchdog は1台の pgpool-II で実行された failover command(ノードの追加、切り離しなど)を他の全ての pgpool-II で実行します。failover command が実行されると、watchdog は以下の情報を他の pgpool-II へ通知します。
- コマンド種別(以下のどれか)
- attach: ノードの追加
- detach: ノード切り離し
- promote: プライマリへの昇格
- 対象ノードのリスト
実際の振る舞いを確認してみます。server1, server2 の2つの pgpool-II が2台の PostgreSQL ノード(db1, db2)を共有しているとします。まずは pcp_node_info コマンドでそのことを確認します。
$ pcp_node_info 0 server1 9898 postgres pass 0 db1 5432 2 0.500000 $ pcp_node_info 0 server1 9898 postgres poss 1 db2 5432 2 0.500000 $ pcp_node_info 0 server2 9898 postgres pass 0 db1 5432 2 0.500000 $ pcp_node_info 0 server2 9898 postgres pass 1 db2 5432 2 0.500000
次に pcp_dertach_node コマンドで、server1のノード0番(db1)を切り離します。
$ pcp_detach_node 0 server1 9898 postgres pass 0
server1, server2 の両方でノード 0 番(db1)が切り離されている(状態が 3 になっている)ことを確かめます。
$ pcp_node_info 0 server1 9898 postgres pass 0 db1 5432 3 0.500000 $ pcp_node_info 0 server1 9898 postgres pass 1 db2 5432 2 0.500000 $ pcp_node_info 0 server2 9898 postgres pass 0 db1 5432 3 0.500000 $ pcp_node_info 0 server2 9898 postgres pass 1 db2 5432 2 0.500000
5.3.3. リカバリ開始・終了タイミングの通知
pgpool-II は レプリケーションモードの オンラインリカバリ(2nd ステージ)を行っている最中は新しい接続を受け付けないようになっています。watchdog で複数の pgpool-II が 複数の PostgreSQL を共有する場合も、DB 状態の一貫性を保つため、1つの pgpool-II でオンラインリカバリの 2nd ステージが始まると他の pgpool-II でも新しい接続を受け付けなくなります。watchdog はリカバリの開始と終了のタイミングを他の pgpool-II へ通知することでこの機能を実現しています。
5.3.4. フェールオーバ/フェールバックコマンドの排他実行
フェイルオーバ、ファイルバックが発生した場合、 failover_command, failback_command, follow_master_command )で指定したコマンドは、インターロック機構により、1つの pgpool-II でのみ実行されます。
watchdog 使用時にフェイルオーバ・フェイルバックが開始されると、各 pgpool-II はアクティブ pgpool-II に問い合わせコマンド実行権を要求します。 このとき一番最初に要求を出した pgpool-II がその権利を取得し「ロックホルダー」となります。コマンドはロックホルダーにのみ実行され、他の pgpool-II はコマンドを実行しません。また、他の pgpool-II はロックホルダーのコマンド実行タイミングと同期をとり、内部状態の更新(新プライマリの更新など)は、バックエンドのフェイルオーバ(スタンバイからプライマリへの昇格など)の後に行われるようにします。
このインターロック機構はバージョン 3.3 からの新機能です。従来は、これらのコマンドは全ての pgpool-II で実行されていました。
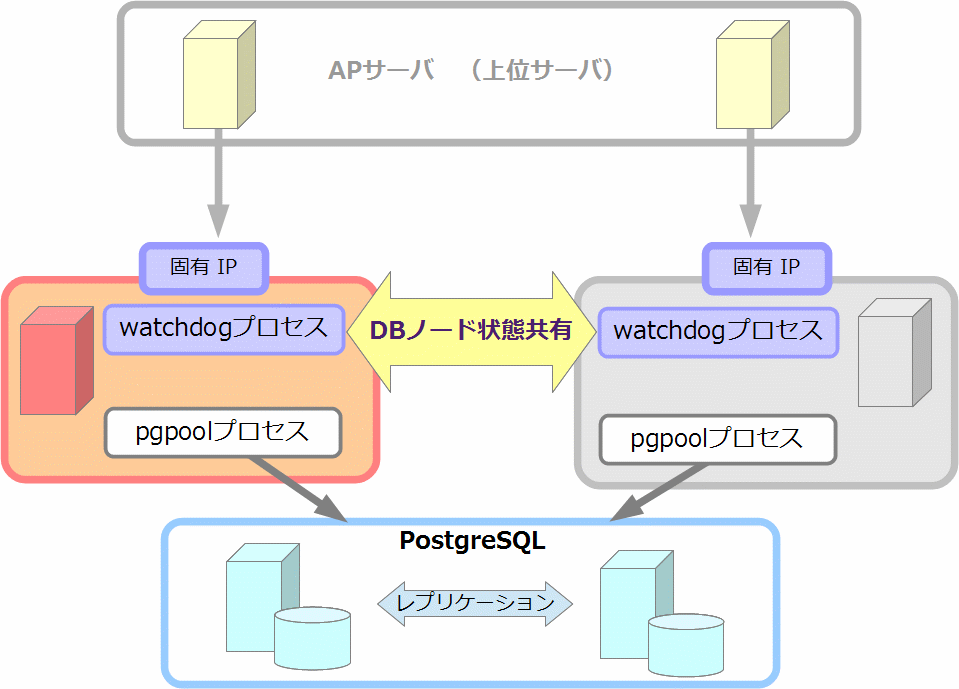
5.3.5. マルチマスタ構成
以上のように pgpool-II 間で DB ノードの状態が共有されることを利用して、複数の pgpool-II を同時に利用するマルチマスタ構成をとることが可能です。この構成は主に負荷分散を目的としており、下図のように複数のアプリケーションが仮想 IP ではなく固有 IP を介して別々の pgpool-II に接続します。 この構成の場合、仮想 IP は必要がないので delegate_IP には何も設定する必要がありません。
5.4. スプリットブレイン対策
複数の pgpool-II の間のネットワークが遮断された場合、互いに「ダウンしたのは相手である」と判断するため、結果としてアクティブの pgpool-II が複数できてしまうことが起こり得ます。この状況をスプリットブレイン(分離脳)と呼びます。
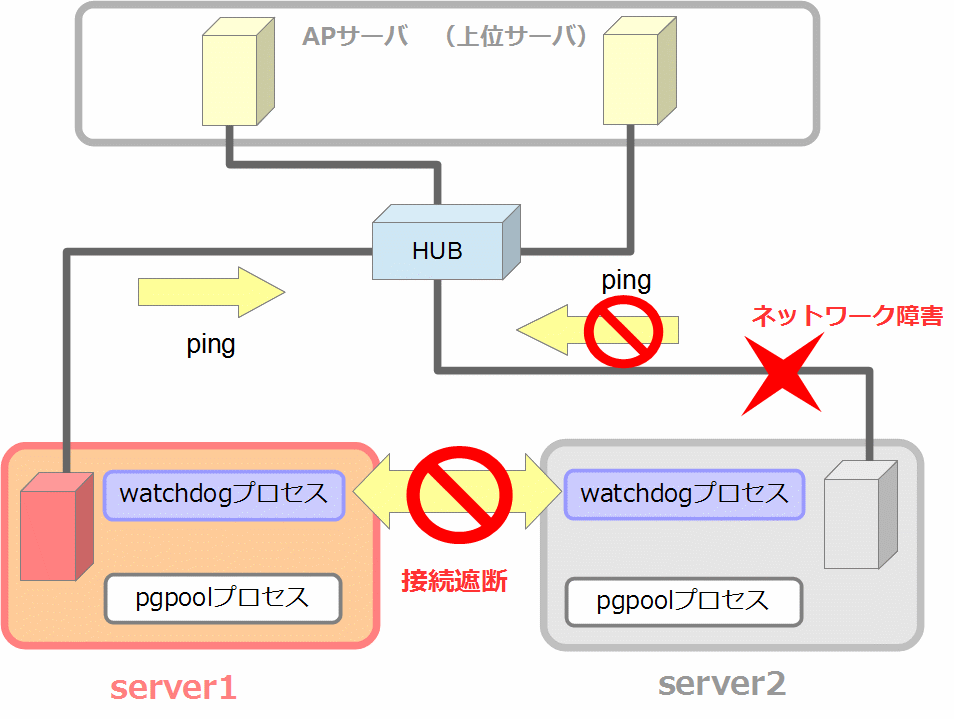
5.4.1. 上位サーバへの接続確認
watchdog では 上位サーバへの接続をチェックすることでスプリットブレイン対策を行っています。下図は pgpool-II 間の接続が遮断された状況の例です。赤い×印の所でネットワーク障害が起きているため、server2 は上位サーバとの接続を確認できません。server1 はサービス提供可能ですが、server2 はサービス提供ができない状態です。この場合アクティブになるのは server1 の方が妥当です。このように、上位サーバへの接続(ping)が確認できない場合には「ダウンしているのは自分自身である」と判断し、あえてアクティブに昇格せず、自分をダウン状態とみなすことで、watchdog はスプリットブレインを回避しています。 *4)
5.4.2. ハートビート用ネットワークの冗長化
上位サーバへの接続確認に用いるネットワークと、ハートビート信号の交換に用いるネットワークが異なる場合には、上述の方法ではスプリットブレインは回避できません。ハートビートモードの場合、watchdog はハートビート信号が途切れた pgpool-II をダウンと見なすため、ハートビート信号の交換に用いているネットワーク(インターコネクト)が切断された場合には、スプリットブレイン状態になってしまいます。
これの対処策としてハートビート用ネットワークを複数設定し冗長化することが可能です。例えば、ハートビート用送受信用の IP として、server1 が 192.168.100.101, 192.168.200.102 の2つ、server2 が 192.168.100.102, 192.168.200.102 の2つを持っている場合、以下のように heartbeat_destinationX, heartbeat_destiantion_portX を設定することができます。
- server1
heartbeat_destination0 = '192.168.100.102' heartbeat_destination_port0 = 9694 heartbeat_device0 = '' heartbeat_destination1 = '192.168.200.102' heartbeat_destination_port1 = 9694 heartbeat_device1 = ''
- server2
heartbeat_destination0 = '192.168.100.101' heartbeat_destination_port0 = 9694 heartbeat_device0 = '' heartbeat_destination1 = '192.168.200.101' heartbeat_destination_port1 = 9694 heartbeat_device1 = ''
この場合、例えば 192.168.100.x セグメントのネットワークが遮断された場合でも、 192.168.200.x セグメントのネットワークに異常がなければアクティブ/スタンバイの切り替えは起こらず、スプリットブレインも発生しません。
5.5. 仮想 IP の制御
watchdog は仮想 IP インタフェースの起動/停止のために ifconfig コマンドを、切り替わった IP を周囲に通知するために arping コマンドを使用します。これらのコマンドのパスやオプションは以下のパラメータで指定することができますが、通常はデフォルトから変更する必要はありませ ん。
ifconfig_path = '/sbin'
# ifconfig command path
if_up_cmd = 'ifconfig eth0:0 inet $_IP_$ netmask 255.255.255.0'
# startup delegate IP command
if_down_cmd = 'ifconfig eth0:0 down'
# shutdown delegate IP command
arping_path = '/usr/sbin' # arping command path
arping_cmd = 'arping -U $_IP_$ -w 1'
# arping command
何度か述べているとおり、これらのコマンド実行のため watchdog は root 権限で起動される必要があります。root ユーザによる直接実行でも、sudo コマンドを用いても問題はありません。しかし、pgpool-II の GUI 管理ツールである pgpoolAdmin を用いる場合、これらの方法は使えません。pgpoolAdmin は Web アプリケーションなので、apache ユーザで watchdog を起動する方法が必要になります。
1つの方法は apache の実行ユーザとグループを root に変更することです。実行ユーザは httpd.conf の User, Group ディレクティブで設定することが出来ます。(ただし、この場合は apache の再コンパイルが求められます。)もう1つは以下のように pgpool コマンドの setuid フラグを立てる方法です。これらの方法で、apache ユーザ でも pgpool を root 権限で実行することが可能です。
# chown root bin/pgpool # chmod 4755 bin/pgpool
もう少し安全なものとして pgpool コマンドそのものではなく、ifconfig, arping コマンドの setuid フラグを立てておく方法があります。
# chmod 4755 /sbin/ifconfig # chmod 4755 /sbin/arping
この方法では pgpool 起動時にログに以下の警告が出力されますが、比較的安全に一般ユーザから watchdog を使用することが可能です
pid 15677: watchdog might call network commands which using sticky bit.
しかし /sbin ディレクトリの ifconfig, arping に直接 setuid を立てるよりは、ifconfig, arping コマンドを特定のディレクトリにコピーし、そのコピーされたコマンドに setuid を立てるのがより望ましいでしょう。 その場合には、pgpool-II 実行ユーザ (apache など)にのみディレクトリのアクセス権限を与え、ディレクトリのパスを ifconfig_path, arping_path に指定します。
あるいは、visudo コマンドで pgpool-II 実行ユーザが、ifconfig, arping コマンドをパスワードなしの sudo で実行できるようにしておく方法もあります。その場合には、if_up_cmd, if_down_cmd, arping_cmd には sudo を使ったコマンドを指定し、ifconfig_path, arping_path には sudo コマンドのパス(/usr/bin)を指定します。
(2013 年 8 月 14 日掲載)