
PostgreSQL 8.4 の新機能
NTT オープンソースソフトウェアセンタ 板垣 貴裕
2009年7月1日、PostgreSQL 8.4 がリリースされました。以前のバージョンから1年5ヶ月ぶりのリリースです。数多くの新機能が盛り込まれていますが、大まかに以下のカテゴリに分けて紹介します。今回は、応用SQL、大規模対応に引き続き、運用管理に関する新機能をご紹介します。
公式のリリースノートは PostgreSQL 8.4プレスキットを参照してください。ソースコードと各プラットホーム向けのバイナリもダウンロードできるようになっています。
応用SQLに関する新機能
応用SQLに関する機能では、特に「再帰SQL」と「Window関数」への対応が大きいでしょう。 PostgreSQL は標準SQLに良く準拠していると評価されることが多いのですが、実際には SQL:92, SQL:99 への対応でした。標準SQLも SQL:2003, SQL:2008 という規格が策定されており、それらの新しいSQLへの対応はこれまで若干遅れを取っていました。しかし、8.4 で一気に追いついたと言えそうです。
その他、痒いところに手が届く、以前のバージョンとの互換性や、他DBMSからの移植性の向上に関する機能が追加されています。
再帰SQL (WITH RECURSIVE)
新しいSQL構文として、共通表式 WITH 句と再帰SQL (WITH RECURSIVE) がサポートされました。
共通表式 WITH 句は、サブクエリや結合に似た概念ですが、その結果を複数参照する場合であっても、1回のみ記述すれば済むようになります。
再帰SQL (WITH RECURSIVE) は WITH 句を更に拡張し、SQL のみで繰り返し処理を記述できるようにしたものです。テーブルに木構造のデータが格納されており、これまで自己結合 (セルフ・ジョイン; Self-Join) を繰り返す必要があった処理を簡潔に記述できるようになります。典型的な木構造データの問合せの例を以下に示します。詳しくは『再帰SQL』を参照して下さい。
=# WITH RECURSIVE r AS (
SELECT * FROM tree WHERE id = 1 -- id=1 とその子孫を列挙
UNION ALL
SELECT tree.* FROM tree, r WHERE tree.parent = r.id
)
SELECT * FROM r ORDER BY id;
id | parent
----+--------
1 |
2 | 1
3 | 1
4 | 3
(4 rows)
Window関数
Window関数はテーブルを区間ごとに集計する機能です。古くからSQLには集計機能として GROUP BY がありましたが、Window 関数では複数の行をまとめることはありません。 「連番の付与」「上位10%のみを取得」「歯抜けIDの検索」などを効率的に記述できるようになります。最も単純な連番を付与する例を以下に示します。その他の使い方は『Window関数』を参照してください。
=# SELECT row_number() OVER (), *
FROM (SELECT * FROM tbl ORDER BY sortkey) AS t;
互換性の改善
PostgreSQL 8.3 では文字列型への暗黙のキャストが削除され、8.2 以前のバージョンがそのまま動作しないことがありました。キャストを追加してバージョン互換性を保つこともできたのですが、若干手間がかかります。 キャストを手軽に定義したいという要望に答え、8.4 では以下のような簡単な構文で暗黙の文字列変換が定義できるようになりました。
=# CREATE CAST (integer AS varchar) WITH INOUT AS IMPLICIT;
移植性の改善
それぞれの改良は単体でも嬉しいものもありますが、特に他DBMSとの移植性のためにSQLを共通化したいような場合に役に立つと思います。
- 列の別名定義でASが不要になった
- 「SELECT 列 [AS] 列別名 FROM 表 [AS] 表別名」のように、列別名を指定する際の「AS」が省略できるようになりました(表別名のASは、以前のバージョンでも省略できます)。他DBMSでは AS があるとエラーになるものがあるため、常に省略するようにしておけばSQLを移植する際に混乱がなくなります。
- DISTINCT を GROUP BYに置き換えなくても高速になった
- PostgreSQL のバッドノウハウとして「DISTINCT は遅いので、代わりに GROUP BY を使うべし」というものがありました。DISTINCT は常にソートで処理されるのに対し、GROUP BY では ハッシュ処理 or ソート処理の高速な方が自動選択されたためです。8.4 からは DISTINCT でも GROUP BY と同様に2つの方式が利用されるようになりました。これからは DISTINCT も気軽に使っていけます。
- PL/pgSQLにCASE構文が追加された
- 条件分岐として、IF構文に加えて、Oracle Database の PL/SQL と互換性のあるCASE構文が追加されました。
大規模対応に関する新機能
大規模対応に関する新機能では、以下の改良が入っています。PostgreSQL でも多くのCPUを持つ高性能なサーバで大量のデータを扱う機会が増えてきました。そういった用途に対応するための仕組みが導入されています。
パーティショニングの簡略化
パーティショニングはバージョンアップに伴い少しずつ改良が続いています。8.4 でもパーティショニングがより使いやすくなる改良が2点導入されました。利点や使い方など、これ以外の情報については『パーティショニング』を参照してください。
- constraint_exclusion = partition の追加
- パーティションそれぞれがクエリの検索候補か否かの判定には CHECK 制約が使われています。検索に必要の無いパーティションは早期の段階で検索候補から除外されるため、検索が効率的になります。しかし、CHECK 制約を判定する処理も、決して「無料」ではありません。パーティショニングを利用しない場合には判定を無効化するため、constraint_exclusion という設定パラメータが存在し、パーティショニングを使う場合には「on」、使わない場合には「off」を設定することが通例になっていました。
- バージョン 8.4 では新しく「partition」を設定値として選べるようになりました。CHECK 制約の判定をパーティションだけに限定することで、パーティショニングに無関係のクエリでは判定を免除することができます。今後は、パーティショニングを使う場合も使わない場合も、常に「constraint_exclusion = partition」を選んでおけば良いため、頭を悩ませる必要がなくなりました。
- PL/pgSQL への EXECUTE USING の追加
- パーティショニングでは SELECT, UPDATE, DELETE は各パーティションに自動的に処理を分配してくれますが、INSERT は分配してくれません。そのため、INSERT を割り振るトリガをユーザが定義する必要があります。この処理は、PostgreSQL 8.3 では IF 文を羅列する方法が推奨されていました。しかし、この方法ではパーティションが増減するたびにトリガを書き換えなければなりません。
- 一方、新しく導入された EXECUTE USING 構文を使うと、同一の定義のトリガを使い続けられます。分割キーに基づいてパーティション名を算出し、EXECUTE USINGを使い動的SQLへ new を渡すことができます。これを使うとパーティションのメンテナンスが容易になるでしょう。
-
CREATE FUNCTION insert_trigger() RETURNS TRIGGER AS $$ DECLARE part text; -- パーティション・テーブルの名前 BEGIN -- キー値から計算 part := 'tbl_' || to_char(new.insert_time, 'YYYYMM'); -- new を渡す EXECUTE 'INSERT INTO ' || part || ' VALUES(($1).*)' USING new; RETURN NULL; END; $$ LANGUAGE plpgsql;
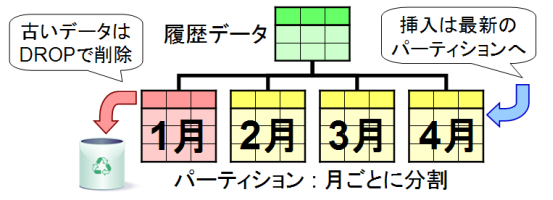
図1 : パーティショニングの構成図
ディスク先読み
処理に必要なデータがまだキャッシュ上に読み込まれていないときには、トランザクションを処理中の各プロセスがそれぞれディスクからデータを読み込みます。以前のバージョンではどんな場合でも素直に1ブロックずつ読み込んでいたのですが、複数のブロックが必要になることが予め分かっている場合には一括して読み込むと効率が良くなります。そのために追加された設定パラメータが effective_io_concurrency です。このパラメータにはストレージが効率的に扱える同時 I/O リクエスト数を設定します。適切な値は概ねディスクドライブ数程度になるようです。この数に応じて、ディスクに対して I/O リクエストを複数同時に発行するようになります。
ただし、8.4 ではまだディスク先読みの適用範囲が限定されており、ビットマップ・スキャン (Bitmap Heap Scan) を行うケースでのみ実行されます。テーブル内の中程度の範囲 (10~20%) のデータを取得する場合に役に立つでしょう。また、ディスク先読みが有効になるのは、今のところ Linux 等の UNIX 系プラットホームに限られます。Windows では先読み機能は働きません。
論理リストア高速化
PostgreSQL の論理バックアップでは、バックアップに pg_dump を、リストアに pg_restore コマンドを使います。この pg_restore に、複数のセッションからパラレルにリストアを行うオプション「--jobs」が追加されました。以下のオプションで指定します。データベース・サーバの CPU 数と同程度の値が適しているでしょう。
-j, --jobs = number-of-jobs
データ投入、インデックス作成、制約の作成などの単位ごとに、PostgreSQL サーバへ複数の接続を行い、マルチスレッドでパラレル・リストアを行います。特に数のCPUを持つサーバで有効です。 ダンプファイルはカスタム形式のみをサポートしているため、pg_dump コマンドでは「--format=custom」または「-F c」オプションを指定してバックアップを取る必要があることに注意してください。
また、pg_dump には大きな変更は無く、バックアップはシングルスレッドでの処理になります。
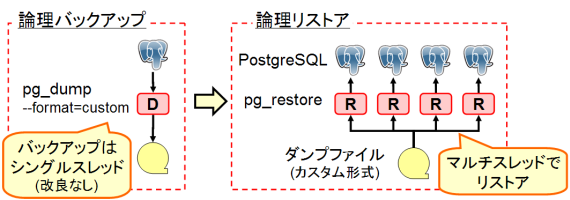
図2 : マルチスレッドによる論理リストア
運用管理に関する新機能
運用管理に関する新機能では、以下の改良が入っています。 システムボトルネックになるコストの高いSQL (スロークエリ) を特定する手段が追加され、VACUUM に関する運用設計の手間も軽減されています。
- スロークエリ解析手段の追加
- デッドロック・ログの改善
- Visibility Map によるVACUUMの高速化
- Free Space Map のメモリ管理の自動化
- pg_terminate_backend() で強制切断
スロークエリ解析手段の追加
実行されたSQLの情報を取得する以下の機能が追加されました。名前が contrib から始まっている機能は、データベース初期化直後の状態では有効化されていませんので、別途モジュールのインストールを行ってください。これらの詳しい使い方については『スロークエリの分析』を参照してください。
- pg_stat_user_functions : 関数の実行時間と回数
- contrib/pg_stat_statements : SQLの実行時間と回数
- contrib/auto_explain : スロークエリの実行計画をログに出力
pg_stat_user_functions は関数のプロファイリングを行う機能です。PL/pgSQL などのストアド・プロシージャを多用しているアプリケーションで有用でしょう。関数ごとに「実行回数」「全体の実行時間」「他の関数呼び出しを含まない実行時間」を取得できます。時間の単位/精度はミリ秒です。この機能を利用する場合には、設定パラメータ track_functions を pl または all に設定する必要があります。デフォルトは none で、統計情報を収集しない設定になっているので注意してください。
=# SELECT * FROM pg_stat_user_functions; funcid | schemaname | funcname | calls | total_time | self_time --------+------------+----------+-------+------------+----------- 16434 | public | proc_1 | 4 | 185 | 185 16738 | public | proc_2 | 5 | 91 | 91 16741 | public | proc_3 | 2 | 76 | 5 (3 rows)
contrib/pg_stat_statements はSQLのプロファイリングを行う機能です。SQLごとに「実行回数」「実行時間」「処理行数」を取得できます。時間の単位は秒/精度はマイクロ秒です。この機能を利用する場合には、「share/contrib/pg_stat_statements.sql」を実行すると共に、postgresql.conf で shared_preload_libraries に 'pg_stat_statements' を設定してください。注意としては、適切な分析をするためには拡張プロトコルまたは Prepared Statement を使う必要があることが挙げられます。例えば pgbench のSQLを解析するのであれば -M extended または -M prepared オプション付きで実行してください。
=# \x
=# SELECT query, calls, total_time, rows
FROM pg_stat_statements ORDER BY total_time DESC LIMIT 3;
-[ RECORD 1 ]------------------------------------------------------------
query | UPDATE branches SET bbalance = bbalance + $1 WHERE bid = $2;
calls | 3000
total_time | 35.9654100
rows | 3000
-[ RECORD 2 ]------------------------------------------------------------
query | UPDATE tellers SET tbalance = tbalance + $1 WHERE tid = $2;
calls | 3000
total_time | 34.7969816
rows | 3000
-[ RECORD 3 ]------------------------------------------------------------
query | UPDATE accounts SET abalance = abalance + $1 WHERE aid = $2;
calls | 3000
total_time | 0.6603847
rows | 3000
contrib/auto_explain はスロークエリの実行計画をサーバログに出力する機能です。スロークエリのSQLを出力する log_min_duration_statement に似ていますが、SQLだけでなく実行計画も記録するのが違いです。この機能を利用する場合には、postgresql.conf で shared_preload_libraries に 'auto_explain' を設定してください。スロークエリの閾値は auto_explain.log_min_duration で指定します(デフォルトは -1 で、無効化されています)。出力されるログは以下のようになります。
LOG: duration: 0.986 ms plan:
Aggregate (cost=14.90..14.91 rows=1 width=0)
-> Hash Join (cost=3.91..14.70 rows=81 width=0)
Hash Cond: (pg_class.oid = pg_index.indrelid)
-> Seq Scan on pg_class (cost=0.00..8.27 rows=227 width=4)
-> Hash (cost=2.90..2.90 rows=81 width=4)
-> Seq Scan on pg_index (cost=0.00..2.90 rows=81 width=4)
Filter: indisunique
STATEMENT: SELECT count(*)
FROM pg_class, pg_index
WHERE oid = indrelid AND indisunique;
デッドロック・ログの改善
デッドロック (deadlock) は、複数のオブジェクトを互い違いの順序でロックすることで処理が進まなくなる状態です (図3)。デッドロックが発生すると、どちらか一方のトランザクションが自動的にロールバックされますが、その際に競合した双方のSQLがサーバログへ出力されるようになりました。以前は出力がロールバックされたSQLのみだったため、どのSQLと競合したのかの解析に手間がかかりました。競合する双方のSQLが取得できるため、デッドロックを引き起こす処理の特定が容易になります。 サーバログへの出力例を以下に示します。
ERROR: deadlock detected
DETAIL:
Process 1956 waits for ShareLock on transaction 8214;
blocked by process 2392.
Process 2392 waits for ShareLock on transaction 8215;
blocked by process 1956.
Process 1956: UPDATE tbl SET value = 'AAA' WHERE id = 1;
Process 2392: UPDATE tbl SET value = 'BBB' WHERE id = 2;
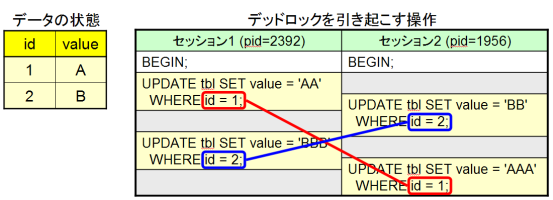
図3 : デッドロックが発生する操作
Visibility Map によるVACUUMの高速化
PostgreSQL は追記型アーキテクチャを採用しており、UPDATE や DELETE の際にガベージが生じます。そのガベージを除去する処理が VACUUMです。8.3 までは VACUUM の際にテーブル全体をスキャンしてガベージを探していましたが、8.4 では Visibility Map によってガベージの位置を追跡し、ガベージのある箇所だけを選択的に処理するようになりました。VACUUM 時の負荷低下と時間短縮の効果が期待できます。極端な話、更新を行っていないテーブルに対する VACUUM では I/O は全く発生しません。
Visibility Map と HOT更新との関係が気になる方もいらっしゃるかもしれませんが、HOT は「ガベージの量を減らす」機能であり、一方 Visibility Map は「ガベージの回収を効率化する」効果を持ちます。基本的には直交した改良です。
Free Space Map のメモリ管理の自動化
VACUUM によってガベージが回収されると、そこは空き領域になり、次回以降の UPDATE や INSERT で再利用されます。どこに空き領域があるのかを追跡する機構が Free Space Map です。Free Space Map が使用するメモリ領域は、8.3 までは起動時に固定量を割り当てていましたが、8.4 では自動的に確保/調整されるようになりました。メモリ割り当て忘れを防ぐとともに、変更のための再起動も不要になります。以前は設定ミスでメモリが不足すると空き領域が再利用されず DB 肥大化の原因になっていましたが、今後は自動管理になるため心配は要りません。
Visibility Map の追加と Free Space Map の改良を併せ、PostgreSQL 8.4 では多くの用途で VACUUM の存在を意識せずに済むようになるでしょう。最後に、VACUUM とこれらの機構の関係を表すイメージ図を示します (図4)。
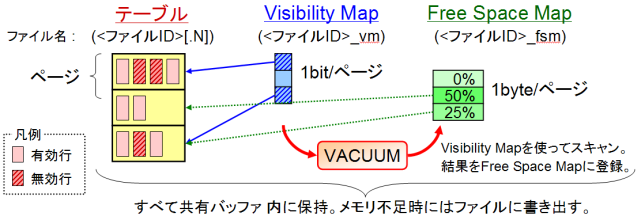
図4 : Visibility Map と Free Space Map
pg_terminate_backend() で強制切断
pg_terminate_backend() 関数が追加され、接続を強制切断できるようになりました。 以前から pg_cancel_backend() 関数は存在していたのですが、これは実行中のクエリを取り消すことしかできません。「<IDLE> in transaction」状態になっている意図しないロングトランザクションを取り消すには、SIGTERM シグナルを直接発行する必要がありました。pg_terminate_backend() 関数は切断を SQL から実行できるので、より安全で扱いが容易です。例えば、特定のホストからの接続のみを全て切断するには、以下のSQLを利用できます。
=# SELECT pg_terminate_backend(procpid) FROM pg_stat_activity
WHERE client_addr = 'ホスト名';
ただし、8.4 であっても、接続を維持したままトランザクションのロールバックのみを行うことはできません。
その他の新機能
上記の3カテゴリの他にも数多くの改良が加わっています。簡単ですが以下に紹介します。
- autovacuum がテーブルと TOAST 領域を別々に VACUUM する
- autovacuum は VACUUM が特に必要ない領域をスキップできるようになりました。Visibility Map も併せ、より効率的な VACUUM が行われるようになりました。
- データベースごとにロケール (locale) を設定できる
- CREATE DATABASE や createdb でデータベースを作成する際にロケールを指定できるようになりました。
- 関数定義にて可変長引数とデフォルト引数が利用できる
- ユーザ定義関数で可変長引数 (VARIADIC) とデフォルト引数を使えるようになりました。これまでは関数をオーバーロード(異なる引数のバージョンの関数を複数定義)する必要がありましたが、その手間を軽減できます。
- CREATE OR REPLACE VIEW で VIEW の末尾に列を追加できる
- VIEW 末尾への追加ならばいったん DROP VIEW する必要がなくなりました。安全のため、既存の列の変更は許されていません。
- TRUNCATE TRIGGER の追加
- TRUNCATE 操作に対してトリガを設定できるようになりました。DELETE トリガとは独立した設定です。
- GIN インデックスの改良
- 複数列インデックスと、前方一致検索がサポートされました。全文検索でも「foo:*」の書式で foo から始まる単語を検索できます。
-
=# SELECT * FROM to_tsvector(textcol) @@ to_tsquery('foo:*'); - 列単位にアクセス制御できる
- 列単位でアクセス権を設定できるようになりました。
-
=# GRANT SELECT (列名) ON 表名 TO ロール名;
- ハッシュ・インデックスがコンパクトに
- ハッシュ・インデックスにハッシュ値のみが格納されるようになりました。場合によっては btree インデックスよりもサイズが小さくなり、高速化が期待できます。ただし、引き続きリカバリには対応していませんので、クラッシュ時には REINDEX が必要です。
- pgbench の改良
- pgbenchに、継続時間 (-T) とクエリモード (-M) オプションが追加されました。定時にベンチマークが完了するようスケジュールしたり、Prepared Statement の性能を測定する場合に役立ちます。
次のバージョンへ先送りされた機能
以下の機能は開発が継続されていますが、8.4 までに十分な完成度が得られなかったため次期バージョン (8.5 改め 9.0) へ先送りされました。希望が多かった機能であるだけに残念ですが、より高い品質で次期バージョンに採用されることを期待しましょう。
- ホット・スタンバイ・クラスタ (Hot Standby) → 9.0へ
- 同期レプリケーション (Synch Rep) → 9.1へ
- 拡張セキュリティ強化 (SE-PostgreSQL) → 9.1へ
- 更新可能ビュー (Updatable views)
まとめ
性能向上の著しかった 8.3 と比べると、8.4 は「使いやすさの向上」に重点が置かれたリリースになりそうです。管理作業、問い合わせ処理、PostgreSQLデータベースのプログラミングを以前に比べ、より容易にするための改良が大量に含まれています。
外部リンク
8.4のリリースと開発版に関する情報の収集には、以下のサイトが参考になります
- PostgreSQL 8.4 リリースニュース
- PostgreSQL 8.4プレスキット
- PostgreSQL 8.4.0 リリースノート
- PostgreSQL 8.4 Update (北海道支部 冬の合同勉強会)
- "What's New in PostgreSQL 8.4", Magnus Hagander, FOSDEM 2009 (PDF)
- Waiting for 8.4 (新機能ウォッチblog)