
パーティショニング : 用途と利点
NTT オープンソースソフトウェアセンタ 板垣 貴裕
パーティショニングとはデータを複数に分割して格納することです。データを分割することにより、性能や運用性が向上し、故障の影響を局所化することができます。巨大なデータを扱う場合にはパーティショニング機能を利用することも検討してみてください。
この記事ではパーティショニングの概要と用途について説明しています。PostgreSQL での具体的な使い方については『パーティショニング : 使い方』を参照してください。
パーティショニングの用途
パーティショニングには大きく分けて「テーブル間の分割」「ノード間の分割」の2つがあります。この記事では主にテーブル間の分割を扱います。
- テーブル間の分割
- 巨大なテーブルを複数のテーブルに分割します。単純に複数のテーブルに分けて格納するだけでも効果はありますが、PostgreSQL は複数のパーティションを1つのテーブルとして見せる機能を持っており、この機能を使うとアプリケーションからはテーブルがどのように分割されているかを意識する必要が無くなります。この記事ではこちらを扱います。
- ノード間の分割
- 巨大なデータベースを複数のノードに分割します。複数台のノードを使うクラスタ構成を取ることになります。PostgreSQL 本体にはノード間の分割を直接サポートしませんが、外部ツールの PGCluster や PL/Proxy などを使うと実現が容易になります。こちらはこの記事では直接は扱いませんが、分割に関する基本的な考え方は参考になると思います。
典型的なデータの分割方法は「レンジ (範囲)」「リスト」「ハッシュ」の3種類です。またそれらを組み合わせた「コンポジット (複合)」分割が用意されている場合もあります。これらそれぞれの手法に対して専用の機能を実装したデータベースも存在しますが、PostgreSQL では特に固定機能としては用意されていません。
レンジ・パーティショニング
値の範囲 (RANGE) ごとに分割する方法です。パーティションそれぞれが互いに重ならないような範囲を受け持ち、その範囲に収まるデータを格納します。
利用例としては、履歴を蓄積するテーブルを日や月単位で分割することがあります。最近のデータにはアクセスが多く、古いデータにはアクセスが少ない場合が多いと思いますが、タイムスタンプ列に基づいて分割することでアクセスの多い最近のデータのみを選択的にキャッシュできることが魅力です。
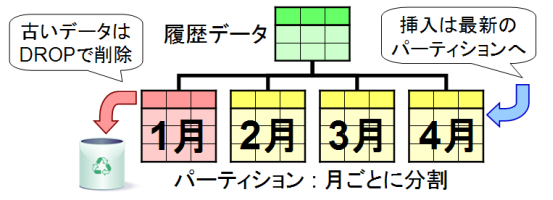
図1 : レンジ・パーティショニング
リスト・パーティショニング
一定数の選択肢 (LIST) から値を選ぶ列がある場合に、その値に基づいて分割を行います。それぞれのパーティションは1つまたは複数の選択肢を受け持つことになります。特にパーティションごとに集計が必要な場合にアクセス範囲を絞れるので有効です。
利用例としては、地域IDに基づく分割があります。ただし、パーティション間の偏りが生じやすいことに注意してください。例えば都道府県であれば最大47個に分割することができますが、多くの場合「東京都」パーティションは他県と比べてデータが大きくなるでしょう。
ハッシュ・パーティショニング
ハッシュ値 (HASH) に基づいて各パーティションに均等に分配します。例えば N 分割する場合には、1~N の整数を返すハッシュ関数を定義し、その返値に基づいて分割を行います。
利用例としては、独立した複数のディスクそれぞれに表領域 (TABLESPACE) を作成し、ディスク間で均等になるようにデータを配置したい場合があります。PostgreSQL では1つのテーブルを、複数の表領域をまたがるように配置することはできませんが、パーティショニングを行うことで似たような状態を実現できます。
また、非常に高い頻度で INSERT を行うテーブルでは、テーブルの末尾にアクセスが集中するためロック競合が発生する場合があります。ハッシュ分割を行うことで実質的に「複数のテーブル末尾」を作ることができ、アクセスを分散するためにも利用されます。
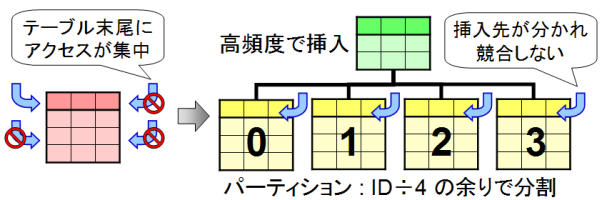
図2 : ハッシュ・パーティショニング
テーブル・パーティショニングの利点と欠点
パーティショニングにはデータを分割できる利点がありますが、その一方、複数のパーティションを完全に透過的には扱えない欠点もあります。パーティショニングの利点と欠点を整理しますので、採用する際の参考にしてください。
パーティショニングの利点
データを分割することで性能面や管理面に利点があります。特にデータベースのサイズがサーバの搭載メモリよりも大きい場合に効果が期待できます。
- 検索範囲の絞込み
- 絞り込み条件がパーティションの分割条件と一致する場合、条件に合わないパーティションは早期の段階で処理対象から外されます。そのため無駄な検索が行われず性能が向上します。例えば月単位で分割している場合での、月ごとの集計処理などで有効です。
- キャッシュの有効活用
- 頻繁にアクセスするデータとあまり使わないデータを分離でき、頻繁にアクセスするデータを格納するパーティションを優先してキャッシュに保持することができます。PostgreSQL のキャッシュはページ単位 (8kB) のため、アクセス頻度が異なる行が同一ページ上にあると、価値の低い行もキャッシュしてしまうのです。
- 一括削除の効率化
- パーティションごとのデータ削除に DELETE ではなく DROP TABLE または TRUNCATE を使うことができます。高速に削除できる上に、削除後の VACUUM も必要ありません。
- データが INSERT した順に配置される
- もし UPDATE も DELETE もしなければ、データは概ね INSERT した順に配置されます。もちろん保証された動作ではありませんが、INSERT した順に配置されることを仮定したアプリケーションは意外に多くあります。例えば、挿入した時刻の順にデータを取得することは(テーブルを先頭から順に読み取るだけなので)高速だと期待してはいませんか? パーティショニングを行えばデータの削除を DROP TABLE または TRUNCATE が使えるため、DELETE と INSERT を繰り返すことでのテーブルの断片化を回避できます。
- 個別のパーティションを意識せずに処理できる
- これは単にテーブルを分割する場合と比べた際の利点です。上記に挙げた利点はパーティショニング機能を使わず、単にテーブルを分割するだけでも効果が得られます。ただ、パーティショニング機能を使えば、アプリケーションは親テーブルのみを処理対象にでき、実際の分割方法を(あまり)意識する必要がありません。既存のアプリケーションのSQLを大幅に書き換えずにデータアクセスを効率化したい場合に役立ちます。
パーティショニングの欠点
PostgreSQL はパーティショニング専用の組み込み機能を持たず、複数のテーブル/継承/CHECK 制約などを組み合わせて実現しています。それが災いし、パーティショニングを行うと性能や機能が低下する場合があります。以下に発生しうるトラブルを挙げますので、トレードオフに注意してパーティショニングを使うか否かを判断してください。回避方法は多くの場合、個々のパーティションを指定したSQLを書くことです。
- テーブルあたりの分割数は最大 100 程度
- パーティションがクエリの対象になるデータを含んでいるか否かの判定は、パーティションそれぞれの CHECK 制約を順にテストすることで行われます。パーティション数に比例する時間がかかるため、テーブルあたりの分割数は 100 程度に抑えてください。
- パーティションを跨るユニーク制約を定義できない
- 複数のパーティションに跨るインデックス (いわゆるグローバル・インデックス) はサポートされておらず、ユニーク性をチェックできません。
- INSERT 性能の低下
- 親テーブルへの INSERT をトリガで子テーブルへ振り分ける処理が追加で必要になるため、テーブルに直接 INSERT するよりも性能は低下します。
- INSERT 結果行数が 0 になる
- INSERT の内部的な動作としては、元の INSERT をキャンセルし、代わりにパーティションに別の INSERT を行うことになります。そのため挿入されなかったと判断され 0 行が返却されます。単に返値をチェックしないようにすればよいのですが、利用しているフレームワーク (O/Rマッピングなど) によっては自動的にチェックしているものがあるので解除してください。
- Prepared Statement と相性が悪い
- バインド変数に分割キーが使われていると、パーティションの早期絞込みが行われないため、性能上のメリットが薄くなります。
- CURRENT_TIMESTAMP と相性が悪い
- 正確には、IMMUTABLE 属性以外の関数との組み合わせでは早期絞込みが行われないという制限です。時刻を取得する関数は利用頻度が高いと思いますが、これらも IMMUTABLE 属性を持ちません。現在時刻の指定には SQL 関数は使用せず、代わりにアプリケーションで値を埋め込んでください。
- 複雑なクエリで性能が劣化する可能性がある
- GROUP BY, ORDER BY, 結合, min/max などのクエリでインデックスが使われなかったり、データを含まないことが自明であるパーティションであってもスキャンされてしまう場合があります。9.1 以降であれば ORDER BY + LIMIT ならば効率的に処理できます。
こうしてみると制限が多いようにも見えますが、複雑なクエリを使わない限りは大きな問題になることは少ないと思います。逆に、複数のパーティションに跨る集計クエリでは、パーティションを個別に扱うようにクエリを書き換える必要が生じることも視野に入れておきましょう。
解消済みのパーティショニングの欠点
以下の問題は最新のバージョンでは解消済みですが、古いバージョンを利用する場合のメモとして残しておきます。
- (~9.0) ORDER BY でインデックスが使われない
- PostgreSQL 9.0 以前では、親テーブルをソートした際に、子テーブルの btree インデックスを張った列で ORDER BY しても、インデックスを利用したソートが行われませんでした。 9.1 以降では、子テーブルのインデックスが利用できます。 特に ORDER BY + LIMIT の効率が向上しています。
- (~8.3) SELECT FOR SHARE/UPDATE ができない
- PostgreSQL 8.3 以前では、行の明示的なロックができません。 UPDATE や DELETE での自動的な行ロックは正しく動作します。 8.4 以降では問題なく利用できます。
続いて、PostgreSQL での具体的なパーティショニングの使い方を説明します。