
pgpool-II レプリケーション構成
SRA OSS, Inc
古跡 智仁
本章では、pgpool-II によるレプリケーション構成について紹介します。 pgpool-II をレプリケーションモードで動作させて使うことで PostgreSQL サーバのレプリケーション構成を構築することができます。
pgpool-II によるレプリケーション
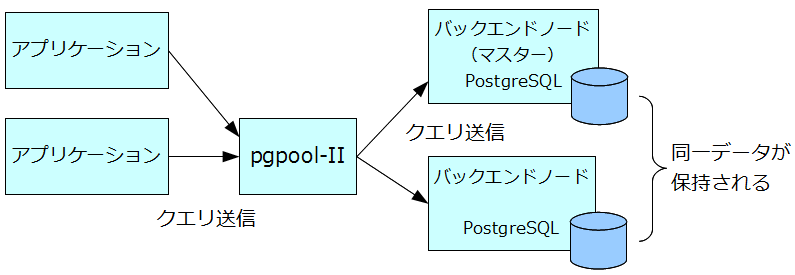
レプリーケーション構成とは、複数ノードにデータの複製を作成する構成のことを指します。pgpool-II は、アプリケーションから受け取った問い合わせをクエリベースで複数ノードに送信して、同じ内容のデータベースを複数ノードで保持することが可能です。ハードディスク障害などで1つのノードが正常に動作しなくなると、これを検知して障害ノードを切り離して縮退動作します。障害検知にあたっては、アプリケーションからのアクセスでエラーになる場合のほか、pgpool-II 自身で定期的なヘルスチェックを行わせることもできます。
pgpool-II ではバックエンドで動作させる PostgreSQL サーバを複数指定しますが、そのうちの一つがマスタとなります。pgpool-II は、アプリケーションから問い合わせを受け取ると、マスタとそれ以外のバックエンドに同じ問い合わせを送信します。ロードバランスモードが指定されている場合には、参照問い合わせ (SELECT文) については、どれか一つのバックエンドにのみ送信します。
pgpool-II はアプリケーションからは普通の PostgreSQL サーバのように見えるため、アプリケーション側では複数のサーバがあることを特に意識することなく、レプリケーションによる障害対策と負荷分散の環境を導入することができます。
pgpool-II は、同じ問い合わせを別々のデータベースに送信してレプリケーションを行っているという仕様から、いくつか制限事項を持ちます。
同じ命令でもサーバによって結果が異なるような処理をして、その結果を書き込むような問い合わせの場合、データが一致しなくなります。典型的には乱数や現在時刻を含む INSERT文や UPDATE文が該当します。これらは「いったん値を生成してから書き込みする」「アプリケーション側で値を生成する」という対策が必要です。pgpool-II の最新版 (2.3.3) では現在時刻の関数については自動でマスタの値を使うように変換してくれます。
また、同時接続されているプロセス間の実行順序によって結果が異なる場合にも注意が必要です。シリアル型やシーケンスを使っている場合、2つのプロセスのどちらを先に実行するかで発番される順序が変わります。バックエンドによって順序が変わるようではいけません。そのほか「予約状況を見て空いてたら予約」といった類の処理も同様の問題があります。これは、問い合わせに行ロックやテーブルロックを加えることで解決できます。pgpool-II では INSERT文について自動的にテーブルロックを追加することができます。これにより最も典型的なシリアル型の値を含むテーブルへの INSERT文については設定だけで対応可能になっています。
pgpool-II のインストール
pgpool-II のインストール方法を紹介します。pgpool-II はビルドに libpq を使用するため、既に libpq がインストールされていることを前提にします。
pgpool-II の最新版ソースコードは、以下のサイトから入手できます。本章では、最新バージョンの 2.3.3 を使用します。
http://pgfoundry.org/projects/pgpool/
ソースコードを展開した後に展開したディレクトリで configure、make、make install を実行することでインストールができます。カレントディレクトリにソースコードがあり、/usr/local (デフォルト) にインストールする場合は以下のように実行します。
# tar xzvf pgpool-II-2.3.3.tar.gz # cd pgpool-II-2.3.3 # ./configure # make # make install
インストールする場所を変更したい場合は、cofigure 実行時に --prefix オプションをつけてディレクトリを指定してください。
また、クライアントライブラリなどがインストールされているディレクトリとして、configure 実行時にデフォルトで pg_config の出力結果が利用されます。pg_config でクライアントライブラリの場所が調べられない場合は、configure 実行時に--with-pgsql オプションでクライアントライブラリのトップディレクトリを指定してください。
プログラムの実行ファイルは /usr/local/bin に、設定ファイルは /usr/local/etc にインストールされます。
pgpool-II の設定
pgpool-II には接続して SQL を実行するインターフェイスとは別に、pgpool-II 自体を制御するためのインターフェイス pcp (pgpool Control Port) が用意されています。pcp を使うには専用のユーザ認証が必要になります。
まず、pcp(pgpool Control Port)の設定のサンプルファイルをコピーします。
# cp /usr/local/etc/pcp.conf.sample /usr/local/etc/pcp.conf
pcp のユーザ認証のために、/usr/local/etc/pcp.conf の設定に以下の行を追加します。
ユーザ名:<md5で符号化したパスワード文字列>
pg_md5 コマンドを使うと、文字列を md5 で符号化して出力ができますのでこれを使うと便利です。
# pg_md5 pass 1a1dc91c907325c69271ddf0c944bc72
レプリケーション用のサンプル設定ファイルがインストールした場所にありますので、このファイルをコピーします。
# cp /usr/local/etc/pgpool.conf.sample-replication /usr/local/etc/pgpool.conf
続いて pgpool.conf の設定を環境に合わせて変更します。 変更後はこのような状態になっています。
pgpool-II の動作するサーバとアプリケーションが別の場合、接続を受け付けるには、以下の設定を変更します。PostgreSQL と同様に '*' を指定することで全てのIPアドレスから接続を受け付けます。
listen_addresses = '<接続を受け付けるIPアドレス>'
pgpool-II は、デフォルトでポート番号9999で動作します。変更したい場合は、以下の設定を変更します。
port = 9999
pgpool-II のプロセスが pid ファイルを書き込めるか確認します。デフォルトでは以下の設定になっていますので、/var/run/pgpoolディレクトリを作成し、書き込み権限を付与してください。
pid_file_name = '/var/run/pgpool/pgpool.pid'
バックエンドで動作させるデータベースの指定を行います。「backend_」で始まるパラメータをいくつか設定します。末尾が0番のものがマスターになります。バックエンドを3台以上置く場合には、backend_hostname2 などと書き足してください。
# バックエンドサーバのホスト名 backend_hostname0 = 'host0.example.org' backend_hostname1 = 'host1.example.org'
# バックエンドサーバのポート番号 backend_port0 = 5432 backend_port1 = 5432
今回はレプリケーションと SELECT文のロードバランスをさせることにします。pgpool.conf.sample-replication では、これらの設定は有効になっていますので変更の必要はありませんが、以下の項目を確認してください。
# レプリケーションモードの設定 replication_mode = true
# ロードバランスモードの設定 load_balance_mode = true
振り分けに対する重み付けは、以下の設定で行うことができます。1 対 1 なら均等に振り分けられます。3 対 7 など任意の数値で比率を表現することができます。0.3 対 0.7 と書いても、30 対 70 と書いても意味は同じです。
# 振り分け重み付けの設定 backend_weight0 = 1 backend_weight1 = 1
定期的にバックエンドのデータベースに接続を試みて障害発生の有無を検知するヘルスチェックは、以下の設定で行うことができます。health_check_period = 0 とするとヘルスチェックを行わないという意味になります。有効にする場合はヘルスチェック用にバックエンドに接続が1つ余計に発生することに注意が必要です。
# ヘルスチェックの有無及び間隔 (秒単位) health_check_period = 0
# ヘルスチェックのタイムアウト値 (秒単位) health_check_timeout = 20
# ヘルスチェックを行う、データベースのユーザ health_check_user = 'nobody'
pgpool-II ではバックエンドの PostgreSQL の接続認証とは別に、pgpool-II 自体でアクセス制御の設定をすることができます。その場合には以下の設定を true に変更します。
# pool_hba.conf を使用してクライアント認証を行う enable_pool_hba = false # アクセス制御する場合は true に
認証はサンプルファイルを元にして設定をします。 書き方は PostgreSQL の pg_hba.conf と似ています。 pool_hba.conf の目的は、アクセスできるクライアントのホストを制限することです。 PostgreSQL から見ると常に pgpool-II が稼動しているホストからのアクセスに見えますので、ホスト制限は pgpool-II 側で行う必要があります。 今回の例では pool_hba.conf は特に設定しないものとします。
# cp /usr/local/etc/pool_hba.conf.sample /usr/local/etc/pool_hba.conf
なお、pgpool-II をレプリケーションモードで使う場合の接続認証には制限があり、trust, reject, password, pam の4つの方式にしか対応していません。
pgpool-II の起動と終了
一通り設定が終わりましたので pgpool-II を起動しましょう。コマンド名は pgpool です。このとき、バックエンドの PostgreSQL をあらかじめ起動しておきます。pgpool-II が先だとヘルスチェック機能が働いたとき「PostgreSQL が落ちている」と判定されてしまいます。
pgpool-II は起動オプションでデーモンモード (デフォルト) と非デーモンモード (-n オプションをつける) を選べますが、必ず非デーモンモードを選択してください。そうでないと pgpool-II のメッセージログを取得できません。pgpool-II を -n オプション付 (非デーモンモード) で起動すると、標準エラー出力にメッセージを書き出します。ファイルにリダイレクトを行う、syslog に転送する logger コマンドを使う、Apache の rotatelogs コマンドを使う、といった方法でログを取ります。
また、メッセージに時刻を含める設定を確認します。ファイルにリダイレクトする場合、rotatelogs を使う場合には必ずログに時刻を含めるようにします。logger コマンドで syslog に転送するのであれば false でも良いです。
print_timestamp = true
今回は固定のファイルにリダイレクトすることにします。起動コマンドは以下のようになります。ここでは root で起動していますが「postgres」などの一般ユーザで動かすこともよく行われます。
[host9]# pgpool -n > /var/log/pgpool.log 2>&1 &
インストールしたディレクトリが /usr/local の場合、デフォルトで以下の3つが設定ファイルとして読み込まれます。
/usr/local/etc/pool_hba.conf /usr/local/etc/pgpool.conf /usr/local/etc/pcp.conf
設定ファイルを別の場所に置いた場合は、-a (pool_hba.conf), -f (pgpool.conf), -F (pcp.conf) オプションを指定して個別にファイルを指定して下さい。
ps コマンドでプロセスが起動していることを確認します。
[host9]# ps u -C pgpool USER PID ... ... COMMAND root 7316 ... ... pgpool -n root 7317 ... ... pgpool: wait for connection request root 7318 ... (snip) ... pgpool: wait for connection request (snip) root 7347 ... ... pgpool: wait for connection request root 7348 ... ... pgpool: wait for connection request root 7349 ... ... pgpool: PCP: wait for connection request
pgpool-II が起動すると、マスタープロセスと pcp 接続用のプロセス以外に、アプリケーションから接続を受け付ける子プロセスが pgpool.conf の num_init_children の数だけ起動します。この数が pgpool-II に対する同時接続数となります。
pgpool-II を停止する時は、stop オプションを使います。なお、PostgreSQL と似た終了オプションが使えます。
- 通常の終了方法 (アプリケーションからの既存の接続が全て終了するまで待ってから停止)
-
# pgpool stop
(-m smart を付与したときと動作は同じです。) 上記を実行すると、新規接続は受け付けません。 - 強制終了 (アプリケーションからの既存の接続を強制的に終了して停止)
-
# pgpool -m fast stop
(fast を immediate に変えても動作は同じです。)
pgpool-II のレプリケーション動作の確認
アプリケーション側から pgpool-II のサーバに接続して、動作確認をしてみます。以下のようなマシンがあるものとします。
| サーバ | ホスト名 | ポート番号 |
|---|---|---|
| PostgreSQLサーバ(マスター) | host0.example.org | 5432 |
| PostgreSQLサーバ | host1.example.org | 5432 |
| pgpool-IIサーバ | host9.example.org | 9999 |
pgpool-II に接続して SHOW pool_status を送信すると、pgpool-II の状態情報が取得できます。このコマンドは pgpool-II だけで処理が行われますので、外部から pgpool-II の死活監視をするときに使われることがあります。
[client ~]$ psql -h host9.example.org -p 9999 -U postgres \
-c "SHOW pool_status" postgres
item | value | description
----------------------+-------+---------------------------------------------
listen_addresses | * | host name(s) or IP address(es) to listen to
port | 9999 | pgpool accepting port number
socket_dir | /tmp | pgpool socket directory
num_init_children | 32 | # of children initially pre-forked
child_life_time | 300 | if idle for this seconds, child exits
connection_life_time | 0 | if idle for this seconds, connection closes
(中略)
backend status1 | 2 | status of backend #1
(67 rows)
続いてデータベースの一覧が見れることを確認します。こんどはバックエンドの PostgreSQL に問い合わせが発生するアクセスになります。
[client ~]$ psql -h host9.example.org -p 9999 -U postgres -l
List of databases
Name | Owner | Encoding | Collation | Ctype | Access privileges
-----------+----------+----------+-----------+-------+-----------------------
postgres | postgres | UTF8 | C | C |
template0 | postgres | UTF8 | C | C | =c/postgres
: postgres=CTc/postgres
template1 | postgres | UTF8 | C | C | =c/postgres
: postgres=CTc/postgres
(3 rows)
データベースを作成するときは、pgpool-II に対して以下のように createdbコマンド (SQL なら CREATE DATABASE コマンド) を実行すれば各バックエンドにデータベースが作成されます。
[client]$ createdb -h host9.example.org -p 9999 -U postgres testdb1
こんどは各バックエンドに直接接続してデータベース testdb1 が作成されているか確認してみます。以下のように両サーバで見えていれば成功です。
PostgreSQL バックエンド(マスター) host0
[client ~]$ psql -h host0.example.org -p 5432 -U postgres -l
List of databases
Name | Owner | Encoding | Collation | Ctype | Access privileges
-----------+----------+----------+-----------+-------+-----------------------
postgres | postgres | UTF8 | C | C |
template0 | postgres | UTF8 | C | C | =c/postgres
: postgres=CTc/postgres
template1 | postgres | UTF8 | C | C | =c/postgres
: postgres=CTc/postgres
testdb1 | postgres | UTF8 | C | C |
(4 rows)
PostgreSQL バックエンド host1
[client]$ psql -h host1.example.org -p 5432 -U postgres -l
List of databases
Name | Owner | Encoding | Collation | Ctype | Access privileges
-----------+----------+----------+-----------+-------+-----------------------
postgres | postgres | UTF8 | C | C |
template0 | postgres | UTF8 | C | C | =c/postgres
: postgres=CTc/postgres
template1 | postgres | UTF8 | C | C | =c/postgres
: postgres=CTc/postgres
testdb1 | postgres | UTF8 | C | C |
(4 rows)
縮退動作
次に片方のバックエンドを停止したときに、縮退して動作するかどうか確認してみます。host1 の PostgreSQLを停止してみます。immediate指定の停止は、終了処理をせず直ちに停止するというもので、障害で停止したのと似た状態になります。
[host1]$ pg_ctl -D /var/pgsql/pgdata -m immediate stop
host1 の PostgreSQLを停止後、pgpool-II からアクセスをすると接続エラーが発生しました。
[client]$ psql -h host9.example.org -p 9999 -U postgres postgres
psql: server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
ここで障害が検知され縮退が行われています。再度アクセスすると今度は接続できます。SHOW pool_status で確認すると末尾の項目 backend status1 が、稼働中を表す 2 でなく、停止中を表す 3 になっています。
[client]$ psql -h host9.example.org -p 9999 -U postgres postgres
psql (8.4.4)
Type "help" for help.
postgres=# SHOW pool_status;
item | value | description
-------------------+-------------------+------------------------
(中略)
backend status0 | 2 | status of backend #0
backend_hostname1 | host1.example.org | backend #1 hostname
backend_port1 | 5432 | backend #1 port number
backend_weight1 | 1073741823.500000 | weight of backend #1
backend status1 | 3 | status of backend #1
(67 rows)
pgpool-II では縮退発生時に、通常のアプリケーションからのアクセスでエラーが発生してしまいます。バックエンドの停止の仕方、あるいは障害の検知のされ方によっては、アプリケーションにバックエンドノードの障害の影響を及ぼさずに済むケースもありますが、基本的には縮退時にエラーが出ることが避けられないといえます。
オンラインリカバリ
pgpool-II ではバックエンドの一つがダウンした場合、自動的に縮退してサービスが維持されますが、いずれは復旧して元のバックエンドノード数に戻したいところです。復旧するには、いったん pgpool-II と PostgreSQL を停止して、復旧させるサーバにデータベースクラスタのディレクトリをコピーして、改めて起動するという方法と、サービスを止めずに復旧させる方法があります。後者をオンラインリカバリと呼びます。
オンラインリカバリは2段階の処理で実現されます。まず、運用を続けたままデータベースクラスタのコピーを取得します。この段階をファーストステージと呼びます。次に、短時間だけアプリケーションから pgpool-II への処理要求をブロックして (待たせて)、その間にファーストステージでコピーしている最中に変更された部分についても復旧先データベースクラスタに反映させます。この段階をセカンドステージと呼びます。最後に復旧先の PostgreSQL を起動して、ブロックしていた処理を再開して、リカバリが完了します。
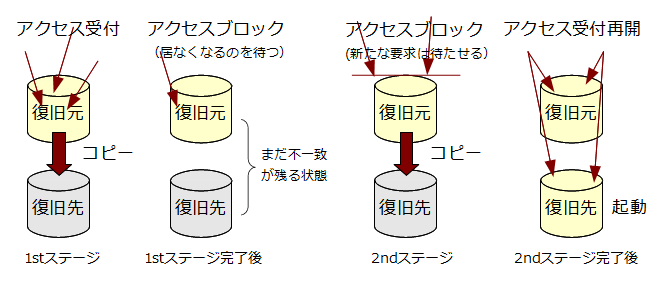
それでは、先ほどフェイルオーバーしたバックエンドをオンラインリカバリで復旧させてみます。ファーストステージとセカンドステージで実行する具体的な処理は任意に指定できます。ここでは PostgreSQL の PITR 機能を使った方法を試します。各バックエンドで archive_mode = on (アーカイブログを取る) という設定が行われる場合に使える方法です。
オンラインリカバリに pgpool-II は PostgreSQL の C言語関数を使用します。全てのノードで以下のようにしてデータベースにインストールする必要があります。template1 となっていますが、これはオンラインリカバリ用のスクリプトの接続先に指定するデータベースであれば何でも構いません。全てのデータベースにリカバリ用関数をインストールする必要はありません。
リカバリ用関数をインストール[host0]# cd pgpool-II-2.3.3/sql/pgpool-recovery [host0]# make install [host0]# psql -p 5432 -U postgres -f pgpool-recovery.sql template1
使用する環境に応じて、設定ファイル pgpool.conf の変更が必要になります。
# マスタ/スレーブサーバのデータベースクラスタ backend_data_directory0 = '/var/pgsql/pgdata' backend_data_directory1 = '/var/pgsql/pgdata'
# オンラインリカバリを行うための、PostgreSQL のスーパーユーザとパスワード recovery_user = 'postgres' recovery_password = 'password_for_postgres'
# データ同期に使用するスクリプトを指定 recovery_1st_stage_command = 'recovery_1st_stage.sh' recovery_2nd_stage_command = 'recovery_2nd_stage.sh'
# ファーストステージからセカンドステージに移行する際のタイムアウト時間 (秒) recovery_timeout = 90 client_idle_limit_in_recovery = 0
最後のタイムアウト時間 recovery_timeout は、セカンドステージに移行するときに、その時点で処理中の接続が終了するのを待つ時間です。この時間を過ぎるとオンラインリカバリは中断され、失敗して終わります。client_idle_limit_in_recovery は、リカバリ中にいつまでも接続中で何の処理もしないクライアントがいるときに、これを強制的に切断する設定です。0 より大きい数値の場合、その秒数を超えると切断します。
なお、本当はこれらは最初のセットアップ時に指定しておくべき項目です。これらの設定は pgpool-II をしないと反映させることができません。本記事に順に動作を試している方はここで pgpool-II を停止、起動させて、設定を反映させてください。
以下に示すリカバリ用のスクリプトを用意します。 これらを実行権限をつけて、データベースクラスタ内の pgpool.conf で指定した場所に配置します。 また、データベースクラスタに pgpool_remote_start というスクリプトを配置します。
recovery_1st_stage.sh
#!/bin/sh
psql -p 5432 -U $USER -d template1 \
-c "select pg_start_backup('pgpool-recovery')"
echo "restore_command = 'scp $HOSTNAME:/var/pgsql/archive/%f %p'" \
> $1/recovery.conf
rsync -C -az --delete -e ssh --exclude postmaster.pid \
--exclude postmaster.opts \
--exclude pg_log --exclude pg_xlog $1/ $2:$3/
psql -p 5432 -U $USER -d template1 -c "select pg_stop_backup()"
rm -rf $1/recovery.conf
ssh -T $2 "rm -rf /var/pgsql/archive/*" \
2>/dev/null 1>/dev/null < /dev/null
ssh -T $2 "mkdir -p $3/pg_xlog/archive_status" \
2>/dev/null 1>/dev/null < /dev/null
recovery_2nd_stage.sh
#!/bin/sh psql -p 5432 -U $USER -d template1 -c "select pg_switch_xlog()" sleep 3pgpool_remote_start
#!/bin/sh
ssh -T $1 /usr/local/bin/pg_ctl -w -D $2 start \
2>/dev/null 1>/dev/null < /dev/null &
リカバリスクリプトは以下の引数が与えられて呼び出されます。スクリプト中で $1、$2、$3 という呼び出し引数に対応した変数を利用しています。
- 第1引数($1) : ローカル(リカバリ複製元)のデータベースクラスタパス
- 第2引数($2) : リカバリノードのホスト名
- 第3引数($3) : リカバリノードのデータベースクラスタパス
各スクリプトは PostgreSQL から起動されます。したがって実行するユーザは PostgreSQL の実行ユーザ (postgres) になります。データのコピーに rsync コマンドを使っています。また、あらかじめバックエンドサーバ間のパスワード入力なしで postgres ユーザが ssh でログインできるようにしておきます。また、アーカイブログは /var/pgsql/archive に格納されているものとして記述しています。
オンラインリカバリを行うには、pcp_recovery_node コマンドを使います。以下のコマンドでバックエンド1番のリカバリを行わせます。ユーザ名とパスワードは pcp.conf に記述したものを用います。先頭の引数はこのコマンド自体のタイムアウト時間です。
[client]$ pcp_recovery_node 100 host9.example.org 9898 ユーザ名 パスワード 1
エラーメッセージが出なければ完了です。以下のように SHOW pool_status でオンラインリカバリの成功を確認しましょう。「backend status1」が 2 になっていればリカバリに成功しています。
[client]$ psql -h host9.example.org -p 9999 -U postgres \
-c 'SHOW pool_status' postgres
リカバリに失敗した場合には、pgpool-II のログを確認してください。どのステージまで処理が行われたのかが分かります。最後の PostgreSQL の起動で失敗しているようでしたら、PostgreSQL のログを確認します。失敗する原因は設定やスクリプトの誤りをはじめ様々考えられます。リカバリに失敗しても、現在稼動しているバックエンドノード、pgpool-II がおかしくなることはありません。オンラインリカバリはやり直しが効く処理ですので、問題点を直して再度リカバリを試みることを繰り返せばよいわけです。
おわりに
今回は pgpool-II を使ったレプリケーション構成の導入方法を紹介しました。
実際のシステムでは pgpool-II の部分に HAクラスタを適用したり、PostgreSQL が動くバックエンドサーバと同居させたりといった工夫が行われます。