
PostgreSQLでXMLを処理してみよう!(第2回)
XPathの基礎 ~XMLデータ内を検索するPostgreSQL XPath機能の紹介~
響 楽人
前回は、XML型を使ってXMLデータをPostgreSQLに格納できることを確認しました。その際、格納されたXMLデータを取り出す例で、条件を付けるためにXPathと呼ばれる記述法を一部使いました。そこで今回は、格納したXMLデータを取り出す時に、様々な条件を付けて、XMLデータの特定の一部分にアクセスすることのできるXPathの記述法について説明します。PostgreSQLでは8.3から標準でXPath式を評価する機能が追加されています。
ところで、今回の記事のタイトルに “検索” とありますが、ふつう“検索”というとテキストでの検索をイメージすることでしょう。しかし、XPathを使ったXMLデータ内の「検索」はそれとは異なります。情報がフラットな形で表現されているテキスト情報とは違い、XMLデータは構造化されており、それ自体がデータベース化された情報のようなものだからです。XMLデータ型に格納されているデータには、単なる値だけではなく、構造情報が含まれています。その構造を理解した上でその中のデータを “検索” するのがXPathなのです。
XPathについての理解はXSLT(XML構造変換の規格)を使って別のXMLやHTMLに変換するときにも必要です。(XSLTについては本連載の4回以降で取り上げる予定です。)
XPathとは?
XPath(XML Path Language)とは、XMLデータ内の要素や属性など、XMLで表現された情報の一部分にアクセスするための指定記述です。RDBのカラムには通常、テキストや数値が入っており、それを一つのものとして扱うのが基本ですが、XML型のデータの場合、XPathを使えばさらにXMLで表現された構造情報を意識してデータを取り出せるのです。RDBの表は2次元の構造情報であるのに対し、XMLはツリー構造をした構造情報と見なせるので、これはちょうど、RDBの一つのカラム内にツリー構造という別の形をした構造化情報が存在するようにも見えます。
そのようなXMLの構造化情報は、タグに注目して検索します。XMLはテキストで表現されてはいますが、このタグに注目した検索は全文検索とは異なるものです。例えば、XMLのタグを使って表現された <author> 要素だけを検索対象とすることができます。この “検索” はXMLで表現されたツリー構造をたどりながら行います。そのたどり方を指定するのがXPathなのです。
PostgreSQLは、XMLデータ型によってタグ付きのXML情報を格納することができるだけでなく、その中の構造情報を認識できるXPathをサポートしているので、2次元のRDBとツリー構造のXMLという2つの情報構造を扱える非常にパワフルな機能を備えているのです。
では、XPathではどのような書き方をしてXMLデータ内部のツリー構造をたどるのか具体的に見てみましょう。本連載の第1回では、「books」列の中の<author>要素が「いくた やすし」である <title> 要素のみを「t_books」テーブルから取り出すために以下のようなSELECT文を使いました。xpath(...) の中で「 ' 」で挟まれている部分がXPathの記述です。
- XPathを含むSELECT文
-
SELECT xpath('/book[author/text()="いくた やすし"]/title', books) FROM t_books; - 格納された3つのXMLデータ
-
<book> <title>エックスエムエルとポスグレ</title> <author>いくた やすし</author> <author>まえだ たかし</author> <publisher>SQL出版</publisher> </book>
<book> <title>ポスグレとエックスパス</title> <author>いくた やすし</author> <publisher>亀の本屋</publisher> </book>
<book> <title>ポスグレとエックスエスエルティー</title> <author>まえだ たかし</author> <publisher>象ブックス</publisher> </book>
- XpathによるSELECT文実行結果
-
xpath --------------------------------------------- {<title>エックスエムエルとポスグレ</title>} {<title>ポスグレとエックスパス</title>} {} (3 rows)
格納された3つのXMLデータのうち、author が "いくた やすし" という値を持つXMLデータのtitle要素にアクセスしています。
XPathの読み方
上記の結果を取り出すために使ったXPathの記述 '/book[author/text()="いくた やすし"]/title' について順を追って説明します。
XPathは左から右に読み、XML データを要素の階層構造のツリーと見立ててたどりつつ、絞り込み条件の指定があれば順次適用して解釈します。
'/book[author/text()="いくた やすし"]/title'
- 黄色で示した最初のスラッシュ“/”とその右に書かれている“book”によってbook要素が指定されます。これは省略した書き方で、正式には/child::bookと書きます。「child::」は、起点(現在位置)からXMLデータのツリー構造をたどる方向を指定するものです。この方向をXPathでは軸(Axis)と呼びます。(軸については、この記事の途中で詳しく説明しています)。child::については、省略したほうが直観的にもツリー構造を上から下に順にたどっているイメージが湧くので、省略する場合がほとんどです。
このステップで、まずルート要素の子要素のbook要素が選択されました。
'/book[author/text()="いくた やすし"]/title'
- [ と ] の間に条件をつけて絞り込むための式が入っています。ここで、前のステップで絞り込まれた要素のうち、式の条件を満たすもののみ選択されます。それで、この式で指定された条件を見てみましょう。
'/book[author/text()="いくた やすし"]/title'
- book要素の子要素のauthor要素のという意味です。
'/book[author/text()="いくた やすし"]/title'
- ‘text()’は要素の配下にあるテキスト情報を指すための記述法です。
/book[author/text()="いくた やすし"]/title'
- 抽出されたテキストが「いくた やすし」と一致するかどうかをテストします。
- つまり、[ ] 内の式によって、author要素の中に書かれたテキストが「いくた やすし」であるものという条件が指定されているのです。
/book[author/text()="いくた やすし"]/title'
- 先ほど説明しましたが、これもchild::titleの省略した書き方です。つまり、author要素の中に書かれたテキストが「いくた やすし」であるものという条件に合うbook要素の子要素のtitle要素にたどり着きます。
ここでXPathの記述が終わっていますので、この時点での結果が返されます。
第1回の記事では、XMLに書かれた情報に条件を付けてデータを取り出せるという説明でさりげなくこの例を使いましたが、結構細かい指定を行っていたことになります。
XPathの文法
では、前述のようなXPath式を自在に書けるようにするため、XPathの仕組みと考え方を説明しましょう。
ロケーションパス(Location Path)
ロケーションパスは、段階的に要素や属性をたどるためのロケーションステップと呼ばれるものをスラッシュでつぎつぎとつないだものです。ロケーションステップは、次にたどるべき要素や属性に条件を付けて指定するもので、構造化されてちょうどツリーのように見えるXMLデータの階層をたどるために使います。
このロケーションステップの記述の仕方は、要素名や属性名を絞り込む「ノードテスト(Node Test)」、その絞り込みの際に階層をたどる方向を表す「軸(Axis)」、さらに、そのようにして絞り込まれた要素や属性に対する条件を付けるための「述語(Predicate)」および述語の中に書く「式(Expression)」で成り立っています。次の図をご覧ください。
- 図1 ロケーションパス
上の図には「軸」が表わされていませんが、スラッシュとノードテスト(bookやtitle)の間に隠れており、それが省略されたものとなっています。これについてはこの後説明します。では以下に、このノードテスト、軸、述語、式について説明します。
注)図1の「述語」の中に”authot/text()”という記述がありますが、XPathでは、ロケーションパス自体が式の一つの形式です。つまり、ロケーションパス内の [ ] に式を書くことができますが、その中で使うロケーションパスでさらに [ ] で式を使ったXPath指定も書くことができます。
ノードテスト(Node Test)
ノードと呼ぶと、とたんに「抽象的で難しい言葉が出できたなあ」と思われるかもしれません。でも、まずは単純に、XMLで記述する「要素」や「属性」のことと考えて、XMLの階層構造をイメージしてください。XMLは、最も外側に来る一つのタグで括って記述することになっていますから、この要素が「ルート要素」となって、その中の子供の要素がつぎつぎとぶら下がったツリーとなります。属性は、要素ノードにぶら下がる特殊なノードと考えてください。
<author>いくた やすし</author>の「いくた やすし」のように、要素の中に書かれたテキストもノードです。これは“text()”で表します。
軸(Axis)
ここまでのXPathの記述例では、XMLのツリー構造を下の方(子要素の方向)へたどりましたが、XMLツリーのたどり方として、親から子へ一方向にたどるだけでなく、親へ遡ったり、同列の兄弟をたどったり、従属する属性をたどることもできます。起点(現在地点)からどちらヘ向かってツリーをたどるかを表す為に13種類の軸がありますが、それらの意味と省略記述は以下の通りです。
図1で例示した'/book[author/text()="いくた やすし"]/title'では、子ノードの方向を表すchild::が省略されていました。これを省略せずに記述すると'/ child::book[child::author/ child::text()="いくた やすし"]/ child::title'となります。かなり冗長で読みにくいですね。ツリーをたどる場合の多くがchild::ですし、OSのディレクトリ(フォルダ)のパス記述に似ていて直観的にも理解しやすいという理由だと思われますが、child::については省略記述を行うことが多いようです。
| 軸 | 意味 | 省略記述 |
|---|---|---|
| child:: | 子ノード | (何も書かない) |
| attribute:: | 起点ノードの属性ノード | @ |
| self:: | 起点ノード自身 | . |
| parent:: | 親ノード | .. |
| descendant-or-self:: | 起点ノードと子孫ノード | // |
| ancestor:: | 祖先ノード | |
| ancestor-or-self:: | 起点ノードと祖先ノード | |
| descendant:: | 子孫ノード | |
| following:: | テキスト上で起点より後に位置するノードすべて(子孫ノードを除く) | |
| preceding:: | テキスト上で起点より前に位置するノードすべて(祖先ノードを除く) | |
| following-sibling:: | テキスト上で起点より後に位置する兄弟ノード | |
| preceding-sibling:: | テキスト上で起点より前に位置する兄弟ノード | |
| namespace:: | 起点ノードの名前空間ノード |
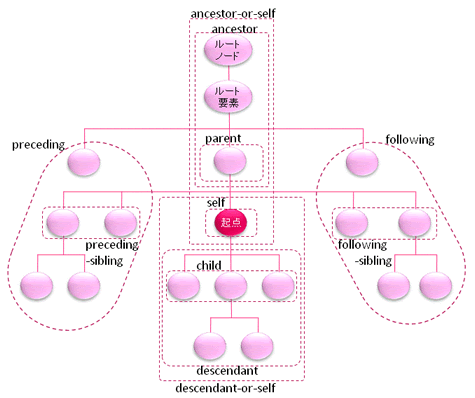
ノードと軸についてのここまでの説明をツリー構造として図示すると次のようになります。

- 図2 ツリー構造
ところで図2のツリー構造の一番上に、「XPathの文法」の「ノードテスト」の説明では出てこなかった「ルートノード」というノードが現れています。XPathではXMLデータを大きく括る最も外側のタグ(要素)の上に目には見えない「ルートノード」と呼ばれるものが存在することになっています。つまり、XMLデータを見たり書いたりするときに意識する最も外側のタグ(要素)である「ルート要素」の上に目に見えない「ルートノード」があると考えるのです。
実は、「XPathの読み方」で例として挙げた'/book[author/text()="いくた やすし"]/title'において、最初のスラッシュ“/”はこの「ルートノード」を指しています。見えないノードを意識しなければならないのは面倒ですが、XPathでは、XMLツリーの一番上にそのようなものがあると考えるものだということで覚えておきましょう。
簡単なXPath記述例
ここまでの説明の内容で簡単なXPathを書くことができます。そこで、述語と式の説明に入る前に、軸とノードテストだけでXMLツリーをたどるXPathを書いて、実際にPostgreSQLで試してみましょう。
まずbooks列 (XML型) をもつ t_booklist テーブルを作成します。
create table t_booklist(books xml);
books列(XML型)に以下のように3冊分の図書データを挿入します。これまでの例に対してcurrency属性付きのprice要素を増やしました。
INSERT INTO t_booklist(books) VALUES('
<book>
<title>エックスエムエルとポスグレ</title>
<author>いくた やすし</author>
<author>まえだ たかし</author>
<publisher>SQL出版</publisher>
<price currency="yen">1200</price>
</book>');
INSERT INTO t_booklist(books) VALUES('
<book>
<title>ポスグレとエックスパス</title>
<author>いくた やすし</author>
<publisher>亀の本屋</publisher>
<price currency="yen">840</price>
</book>');
INSERT INTO t_booklist(books) VALUES('
<book>
<title>PostgreSQL and XSLT</title>
<author>John Brown</author>
<publisher>Elephant Books</publisher>
<price currency="dollar">16.25</price>
</book>');
それでは早速、title要素のテキスト部分だけを抽出するxpath(/book/title/text())を試してみましょう。
- SELECT文:
-
SELECT xpath('/book/title/text()',books) FROM t_booklist; - 結果:
-
xpath ------------------------------ {エックスエムエルとポスグレ} {ポスグレとエックスパス} {"PostgreSQL and XSLT"} (3 rows)
もう一つ、price要素のcurrency属性を取り出してみましょう。currency属性を指定するxpathは/book/price/@currencyです。(属性ノードを指すための軸の正式な書き方はattribute::ですが、ここでは省略記述である @ を使っています)
- SELECT文:
-
SELECT xpath('/book/price/@currency',books) FROM t_booklist; - 結果:
-
xpath ---------- {yen} {yen} {dollar} (3 rows)
属性だけを取り出すというケースは少ないかもしれませんが、XPathでは属性も要素と同様一つのノードと見なしていることを示すために敢えて属性を指定してみました。
述語による条件指定
ではここで、ツリー構造をたどるだけではなく、条件を付けて検索の絞り込みを行う仕組みを説明しましょう。それを行うのが「述語」とその中の「式」と呼ばれる記述法です。
述語(Predicate)と式(Expression)
述語は[式]という形で書きますが、軸::ノードテストで選択されたノード集合のさらにその中のノード一つ一つに関して式を評価し、その結果が真となるものだけを残すことによってノード集合を絞り込むためのものです。
式には、数値を返す式、真か偽かを返す式、ノードを返す式、文字列を返す式がありますが、ここでは直観的に理解できる「値が一致するかどうか」という文字列比較の式を例にあげます。
例: /book[publisher/text()=”亀の本屋”]
publisher/text()=”亀の本屋”という式を含む述語によって、publisher要素の値(テキストノードの値)が“亀の本屋”であるようなbook要素が指定されることになります。
その上で、そのような本のtitleをPostgreSQLで抽出するには/book[publisher/text()=”亀の本屋”]/titleというXPathを使って、「亀の本屋が出版している書籍のタイトル一覧を表示させる」という次のようなSQLを書くことができます。
- SELECT文:
-
SELECT xpath('/book[publisher/text()="亀の本屋"]/title/text()',books) FROM t_booklist; - 結果:
-
xpath -------------------------- {} {ポスグレとエックスパス} {} (3 rows)
ところで、述語内の式である「publisher/text()=”亀の本屋”」の部分は、「publisher=”亀の本屋”」と書いても同じ結果が得られます。
- SELECT文:
-
SELECT xpath('/book[publisher="亀の本屋"]/title/text()',books) FROM t_booklist; - 結果:
-
xpath ------------------------------------ {} {ポスグレとエックスパス} {} (3 rows)
これは、XPathでは、“publisher”のように要素だけが指定されて、比較対象が文字列の場合、要素の下のテキストノードの値を使うという約束があるからです。そのような仕組みを理解していれば、/book[publisher/text()=”亀の本屋”]/titleと書くよりも/book[publisher=”亀の本屋”]/titleと書いたほうが指定が簡潔になりますし、わかりやすいものとなります。
さきほど「簡単なXPath記述例」の最後では、属性ノードをXPathで指定する例として/book/price/@currencyというXPath記述を行いましたが、XMLデータから属性の値だけを取り出すことはあまりないかもしれません。まだ述語と式の説明を行っていなかったために、このような例を示しましたが、ここでもう少し現実的な属性の使い方をしてみましょう。属性の値を要素を絞り込む際の条件として使用します。ここではbook要素を「currency属性の値が“dollar”である」という条件に合致するよう絞り込み、そのような書籍のtitle要素からタイトルを抽出する場合を見てみましょう。
- SELECT文:
-
SELECT xpath('/book[price/@currency="dollar"]/title/text()',books) FROM t_booklist; - 結果:
-
xpath ------------------------- {} {} {"PostgreSQL and XSLT"} (3 rows)
まとめ
今回は、XMLデータの中を条件を付けつつ縦横にたどり、特定のデータにアクセスするためのXPathの読み方、書き方について説明しました。これによってXMLのメリットを十分に引き出すことができます。やや難しい文法説明も含まれていましたが、簡単なXPathを書きながらマスターしてください。次回はXPathを使ったPostgreSQLのより高度なXML処理機能について取り上げます。
(2009年4月23日 公開)