
PostgreSQLでXMLを処理してみよう!(第3回)
第3回XPathの応用-PostgreSQLのXPath機能を利用したデータ照会の実際
響 楽人
SQLでは、SELECT文によって、条件をつけて絞り込みを行ったり集計を行ってデータを取り出すことができますが、PostgreSQL8.3では、この機能をXMLデータに対しても適用することができます。
この記事では、これまでに説明したXPathを使ったXML内の情報検索だけではなく、RDBとしてのPostgreSQLの特徴を活かし、XMLデータとRDBデータをうまく組み合わせたデータベース利用について考えます。さらに、PostgreSQLにはデータ照会を高速化できるインデックス機能が準備されていますが、それをXML型の列を含むテーブルに対して適用しXMLデータの検索を高速化する手法についても取り上げます。
RDBとXMLのハイブリッドなクエリー
前回までの説明で、XML型のカラムに格納されたXMLデータをXPathを使って検索し、任意の要素や属性を抽出できることが分かりましたが、これはXML規格自体の一般的な機能です。今回の記事では、RDB機能とXML型の照会を組み合わせたPostgreSQLならではの利用法について説明しましょう。
例として、社員別に社員番号や名前、部署、年齢などの基本情報プラス職務経歴情報を格納できるようなテーブルを考えます。名前、部署、年齢などの固定的なデータは通常のRDBデータとして表現し、人によって内容や件数に可変性がでてくる職務経歴をXMLデータ型で格納することにしましょう。
まずこれまでと同様、コマンドプロンプトで「psql testdb postgres」と入力し、前回までに作成したtestdbにログインした後、空の「meibo」テーブルを作成します。
- テーブル作成:
-
CREATE TABLE meibo(id integer, name text, department text, age integer, email text, work_history xml);
このテーブルに、次のようなデータを格納します。
| id | name | Department | age | work_history | |
|---|---|---|---|---|---|
| 1031 | 生田靖 | IT事業統括部 | 45 | ikuta@abcd.com | <work-record> <career> <period> <start>1970-04-01</start> <end>1980-03-31</end> </period> <content>製造業向け購買管理システムの開発、大手流通業向け販売管理システム開発</content> <role>プログラマー</role> </career> <career> <period> <start>1980-04-01</start> <end>1985-03-31</end> </period> <content>金融機関向け社内Webシステム開発</content> <role>プロジェクトリーダー</role> </career> <career> <period> <start>1985-04-01</start> <end/> </period> <content>IT戦略部にて企画提案業務</content> <role>マネージャー</role> </career> </work-record> |
| 1088 | 前田孝 | ネットワーク管理課 | 41 | maeda@abcd.com | <work-record> <career> <period> <start>1985-04-01</start> <end>2005-03-31</end> </period> <content>大手電気メーカー向けSCMシステム導入プロジェクト</content> <role>サブリーダー</role> </career> <career> <period> <start>2005-04-01</start> <end/> </period> <content>SCM導入コンサルタント</content> <role>マネージャー</role> </career> </work-record> |
| 1101 | 鈴木花子 | 開発一課 | 33 | suzuki@abcd.com | <work-record> <career> <period> <start>2003-04-01</start> <end>2003-06-30</end> </period> <content>大手コンテンツプロバイダー向け顧客管理システム開発</content> <role>プロジェクトメンバー</role> </career> <career> <period> <start>2003-07-01</start> <end/> </period> <content>SCM導入コンサルタント</content> <role>アシスタント</role> </career> </work-record> |
| 1103 | 田中一郎 | 開発二課 | 32 | tanaka@abcd.com | <work-record> <career> <period> <start>2004-04-01</start> <end>2008-10-31</end> </period> <content>亀ロジスティクス様社内ネットワーク運用保守</content> <role>運用メンバー</role> </career> </work-record> |
| 1076 | 石川順子 | 開発一課 | 23 | ishikawa@abcd.com | <work-record> <career> <period> <start>2008-09-01</start> <end/> </period> <content>亀ロジスティクス様社内ネットワーク運用保守</content> <role>運用メンバー</role> </career> </work-record> |
これをcsv形式のデータとすると以下のようになります(1行分だけ記します)。
-
1076,石川順子,開発一課,23,ishikawa@abcd.com,"<work-record> <career> <period> <start>2008-09-01</start> <end/> </period> <content>亀ロジスティクス様社内ネットワーク運用保守</content> <role>運用メンバー</role> </career> </work-record>"
ところで、データの格納の際、これまではINSERT文の中に直接データとなる文字列を埋め込んでいましたが、今回は数が多いので、csv形式で用意しておいたファイルから一括挿入できるCOPYコマンドを使ってみましょう。ここで読み込むファイルはPostgreSQLデータベースのユーザーがアクセス許可されている必要があります。Windows XPでユーザーpostgresにアクセス許可を与えるには、図1アクセス許可の設定を参考にしてください。
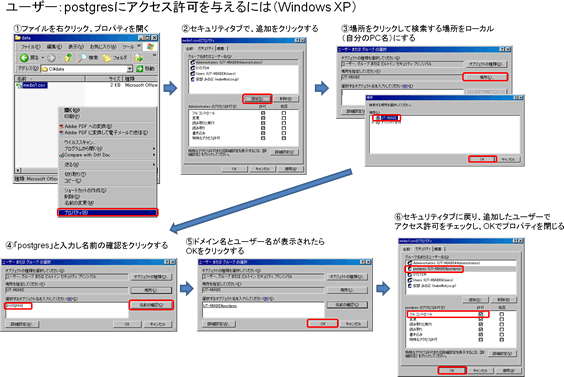
- 図1 アクセス許可の設定クリックで拡大
このようにして、表1のcsvデータを以下のようにCOPYコマンドでmeiboテーブルに格納します。
- データ格納:
-
COPY meibo FROM 'C:/data/meibo1.csv' WITH CSV;
注)この記事を書くにあたっては、上記の表のようなデータをエクセルで作成し、CSVファイル形式を指定して保存することでPostgreSQLに読み込み可能なCSVファイルを作成しました。Windows VISTAを使用する場合は、CSVの文字コードをUTF8にして下さい。
絞り込みのいろいろ
では、通常のRDBデータに加えXML型のカラムがあるmeiboテーブルに対してXPathを使って条件を絞り込んでからデータを取り出してみましょう。
1.WHERE句を使って
WHERE句にはboolean型(真か偽か)を返す式を指定できます。たとえば、meiboテーブルから「“田中一郎”という人のデータ」を抽出するとき、「“田中一郎“という文字をname列に含む」という条件を指定するには以下のようなSELECT文を書きます。これは通常のRDBの照会です。
-
SELECT * FROM meibo WHERE name='田中一郎';
このWHERE句による条件を、meiboテーブルのXMLカラム内のXMLデータに適用するとどうなるでしょうか。例えば職務経歴を調べて「’運用メンバー’を経験したことがある人」の「id」と「名前」と「職務経歴データ」を抽出するとき、どういう条件を指定したらよいでしょうか。
XML型の場合、前回までに説明したXPathを使ってWHERE句を書くことができます。「’運用メンバー’を経験したことがある人」という条件をXPathを使って書く場合、職務経歴が入っているwork_history列のwork-record要素の子要素のcareer要素の子要素のrole要素の値を見て’運用メンバー’かどうかを調べることになりますので、その結果が真となるような行の「id」と「名前」と「職務経歴データ」を取り出せば、望む結果を得ることができます。このSELECT文は以下の通りです。
- SELECT文:
-
SELECT id,name,xpath('/work-record/career',work_history) FROM meibo WHERE '運用メンバー' = ANY( xpath('/work-record/career/role/text()',work_history)::text[]);
- 結果:
-
id | name | xpath ------+----------+---------------------------------------------------------------- 1004 | 田中一郎 | {"<career> : <period> : <start>2004-04-01</start> : <end>2008-10-31</end> : </period> : <content>亀ロジスティクス様社内ネットワーク運用保守</content> : <role>運用メンバー</role> : </career>"} 1005 | 石川順子 | {"<career> : <period> : <start>2008-09-01</start> : <end/> : </period> : <content>亀ロジスティクス様社内ネットワーク運用保守</content> : <role>運用メンバー</role> : </career>"} (2 rows)
少々ややこしくなりましたが、上のSELECT文で注意していただきたいのは、WHERE句でのXMLデータの指定方法です。PostgreSQLでは、XML型そのままではname列のように列名を指定して比較演算子’=’で検索値と比較することができません。そこで、XPath式を ::text[] でテキスト配列型に変換してから比較しています。XPath式を配列型に変換するとどうなるかをXPath式だけ切り出してSELECT文で見てみましょう。
- SELECT文:
-
SELECT xpath('/work-record/career/role/text()',work_history)::text[] FROM meibo; - 結果:
-
xpath -------------------------------------------------- {プログラマー,プロジェクトリーダー,マネージャー} {サブリーダー,マネージャー} {プロジェクトメンバー,アシスタント} {運用メンバー} {運用メンバー} (5 rows)
このように、XPathで取り出したデータが、一行に運用メンバーだけの行もあれば、プログラマー、プロジェクトリーダー、マネージャーと複数を含む行もあるというような場合、比較演算子を使って単に「=‘マネージャー’」 と指定するだけでは目的の行を取得できません。それで、上記の通り ANY() を使って「‘マネージャー’を含むXMLデータが一つでもあれば」という条件を指定しているのです。ちなみにANYを使うとWHERE句の右辺と左辺が入れ替わります。
あるデータ型を他のデータ型に変換したいときは、上のように (変換元 :: 変換したい型) と書きます。他にも CAST(変換元 AS 変換したい型) や、型を関数的に呼び出して 変換したい型(変換元) と書く方法もあります。それぞれ以下のように書けば、上と同じ結果を得ることができます。
- CASTを使う方法:
-
SELECT cast(xpath('/work-record/career/role/text()',work_history) as text) FROM meibo; - 関数を使う方法:
-
SELECT text(xpath('/work-record/career/role/text()',work_history)) FROM meibo;
2.contains関数を使った全文検索的な情報抽出
次に、XPathのcontains関数という便利な機能をご紹介します。これまでXPathを使って検索するときは、ツリー構造から目的の要素をたどるパスを指定し、特定のテキストに完全に一致する値を持つ要素を指定しました。contains関数を使うと、ある文字列の中に特定のテキストに一致するものがあるかどうかという全文検索的な条件指定を行うことができます。
では、具体的にcontains関数をmeiboテーブルに対して使う場合を考えてみましょう。テーブルには個人別に基本情報(id,name,department等)と職務経歴(work_history)が格納されていますが、この中から何らかの開発に従事した経験を持つ人の経歴を取り出すことにします。
「content要素の中に“開発”という文字列を含む」というcontains関数の書き方は、contains(content,"開発") です。1番目の引数には検索対象文字列を入れ、2番目の引数には検索したい文字列を入れます。
このcontains関数はXPathが用意している関数で、XPath式の述語部分に記述できます。全体としてのXPath記述は、/work-record/career[contains(content,"開発")]となります。するとSELECT文は以下のようになります。
- SELECT文:
-
SELECT xpath('/work-record/career[contains(content,"開発")]',work_history) FROM meibo; - 結果:
-
xpath ------------------------------------------------- {"<career> <period> <start>1970-04-01</start> <end>1980-03-31</end> </period> <content>製造業向け購買管理システムの開発、大手流通業向け販売管理システム開発</content> <role>プログラマー</role> </career>","<career> <period> <start>1980-04-01</start> <end>1985-03-31</end> </period> <content>金融機関向け社内Webシステム開発</content> <role>プロジェクトリーダー</role> </career>"} {} {"<career> <period> <start>2003-04-01</start> <end>2003-06-30</end> </period> <content>大手コンテンツプロバイダー向け顧客管理システム開発</content> <role>プロジェクトメンバー</role> </career>"} {} {} (5 rows)
contentに“開発”の2文字が入った<career>要素(職務経歴)が抽出されていることが分かります。
さらに、何からの開発経験を持つ人の「id」、「名前」、「部署」、「年齢」、「e-mail」を取り出すSELECT文と結果は以下のようになります。
- SELECT文:
-
SELECT id,name,department,age,email FROM meibo WHERE xpath('/work-record/career[contains(content,"開発")]',work_history)::text[] <> '{}'; - 結果:
-
id | name | department | age | email ------+----------+--------------+-----+----------------- 1031 | 生田靖 | IT事業統括部 | 45 | ikuta@abcd.com 1101 | 鈴木花子 | 開発一課 | 33 | suzuki@abcd.com
上記のSELECT文では、WHERE句でcontains関数を含むXPath式をtext型に変換してその結果が {} でないという条件をつけています。XPath式自体は一つ上の例のSELECT文で使ったものと同じですので、本来ならば「‘開発’を含むcareer要素を持つ人」という条件で抽出したいところを「{} ではない」という条件で指定しています。これはPostgreSQLの機能として、WHERE句で条件とするために必要な「‘開発’を含むcareer要素」を返すXPath式の結果であるXML型からboolean型への変換がサポートされていないためです。
XMLデータ型とインデックス
次に検索処理を高速化するインデックス機能とXMLとの関係を整理します。インデックスは、列の値を取り出して別途検索用に最適化して保管しておき、検索時に列ではなくインデックス内を探すことで不要なデータにアクセスする無駄な手間を省き、検索処理を高速化することができるという機能です。
PostgreSQLではXMLデータ型に対して比較演算子(>、<、=など)が使えないため、XMLデータ型の列から直接インデックスを作成することはできません。ですから、XPath式にインデックスを作成する場合、text型や配列型(インデックスを作成できる型)に変換する必要があります。
PostgreSQLには複数の種類のインデックスが用意されており、デフォルトはbtree(ビーツリー)インデックスですが、配列型にはGINインデックスを使います。XMLは、同じ要素が複数記述されることが多いので、インデックス付けの対象となるデータが複数繰り返される場合が多いはずです。そこで、配列型のためのGINインデックスがXMLには相性が良いと言えます。XPath式の結果返されるのはノード集合であり、一つのセルの中に複数のデータを含む多次元配列と親和性の高い形式になっていますので、配列型へ変換し、配列型にインデックスを作成できるGINインデックスを使えるのです。
以下に、work-record要素の子要素のcareer要素の子要素のrole要素で指定された値(文字列)に対してGINインデックスを設定する方法を示します。
- GINインデックス作成(GINを使用する場合はUSING ginと指定します):
-
CREATE INDEX x_work ON meibo USING gin((xpath('/work-record/career/role/text()',work_history)::text[]));
成功すると“CREATE INDEX ”と表示されます。
では、このGINインデックスを使って検索してみましょう。次の例ではcountを使って該当するレコードの件数を返すことにします。また、コマンドの先頭にEXPLAIN ANALYZEをつけるとSELECT文の結果そのものではなく、処理の解析結果が表示されます。WHERE句にはインデックスを作成したのと同じXPath式を記述しその後に比較演算子と検索値をつなげます。
- SELECT文:
-
EXPLAIN ANALYZE SELECT count(*) FROM meibo WHERE (xpath('/work-record/career/role/text()',work_history)::text[]) = '{マネージャー}'; - 解析結果:
-
QUERY PLAN -------------------------------------------------------------------------------- Aggregate (cost=10.45..10.46 rows=1 width=0) (actual time=3.848..3.848 rows=1 loops=1) -> Bitmap Heap Scan on meibo (cost=4.27..10.45 rows=2 width=0) (actual time=3.846..3.846 rows=0 loops=1) Filter: ((xpath('/work-record/career/role/text()'::text, work_history, '{}'::text[]))::text[] = '{マネージャー}'::text[]) -> Bitmap Index Scan on x_work (cost=0.00..4.27 rows=2 width=0) (actual time=0.027..0.027 rows=122 loops=1) Index Cond: ((xpath('/work-record/career/role/text()'::text, work_history, '{}'::text[]))::text[] = '{マネージャー}'::text[]) Total runtime: 3.904 ms (6 rows)(読みやすいよう改行を入れています)
中ほどに「Bitmap Index Scan on x_work~」とあり、先に作ったインデックスが使われているのが分かります。後ろから2行目の「Total runtime」は「3.904ms」となっています。
速度の比較をするため、x_workインデックスを削除してから同じ検索処理を行います。
- インデックス削除:
-
DROP INDEX x_work;
成功すると“DROP INDEX ”と表示されます。
- SELECT文(先ほどと同じ):
-
EXPLAIN ANALYZE SELECT count(*) FROM meibo WHERE (xpath('/work-record/career/role/text()',work_history)::text[]) = '{マネージャー}';
- 解析結果:
-
QUERY PLAN -------------------------------------------------------------------------------- Aggregate (cost=25.58..25.59 rows=1 width=0) (actual time=8.439..8.439 rows=1 loops=1) -> Seq Scan on meibo (cost=0.00..25.57 rows=2 width=0) (actual time=8.437..8.437 rows=0 loops=1) Filter: ((xpath('/work-record/career/role/text()'::text, work_history, '{}'::text[]))::text[] = '{マネージャー}'::text[]) Total runtime: 8.479 ms (4 rows)(読みやすいよう改行を入れています)
インデックスを削除したので「Bitmap Index Scan on x_work~」の記述がありません。Total runtimeは「8.479ms」と長くなっています。先ほどのインデックスによる照会が速かったことが分かります。
注)インデックスの計測を行うにあたっては、表1のデータを多くして300件程度のデータを入れたmeiboテーブルを用意しました(表1の5件だけではインデックスをつけても実際の照会時にインデックス機能が使われなかったため)。
まとめ
前回と今回の記事で、PostgreSQLにXML内を検索するためのXPathサポートに加え、RDB利用に書かせないインデックス機能をXMLに対しても適用できることが分かりました。また、PostgreSQLを使えば、リレーショナルデータと組み合わせることによって、単なるXMLデータ格納・取り出しだけではなく、RDBならではの利用も可能であることも分かりました。
次回は、このようにして取り出したXMLデータを加工するためのXSLTについて説明します。
(2009年6月5日 公開)