
PostgreSQL 9.0 の新機能
板垣 貴裕
2010年9月20日、PostgreSQL 9.0.0 がリリースされました。"バージョン 9" を冠する記念すべきリリースです。リリースアナウンスによると、9.0 には組み込みのレプリケーションを始め、数多くの新機能が盛り込まれていると述べられています。バイナリやソースコードは "ダウンロード用ページ" で配布されています。
9.0 では、ホット・スタンバイとストリーミング・レプリケーションを併せて「参照負荷分散レプリケーション」を構成することができます。この記事では、このレプリケーションの概要と、その他の PostgreSQL 9.0 の新機能について紹介します。
参照負荷分散レプリケーション
PostgreSQL 9.0 には「ホット・スタンバイ」と「ストリーミング・レプリケーション」が採用され、これらを組み合わせることで、PostgreSQL でシングルマスタ - マルチスレーブ型の参照負荷分散クラスタが手軽に構築できるようになりました。
ホット・スタンバイ (Hot Standby)
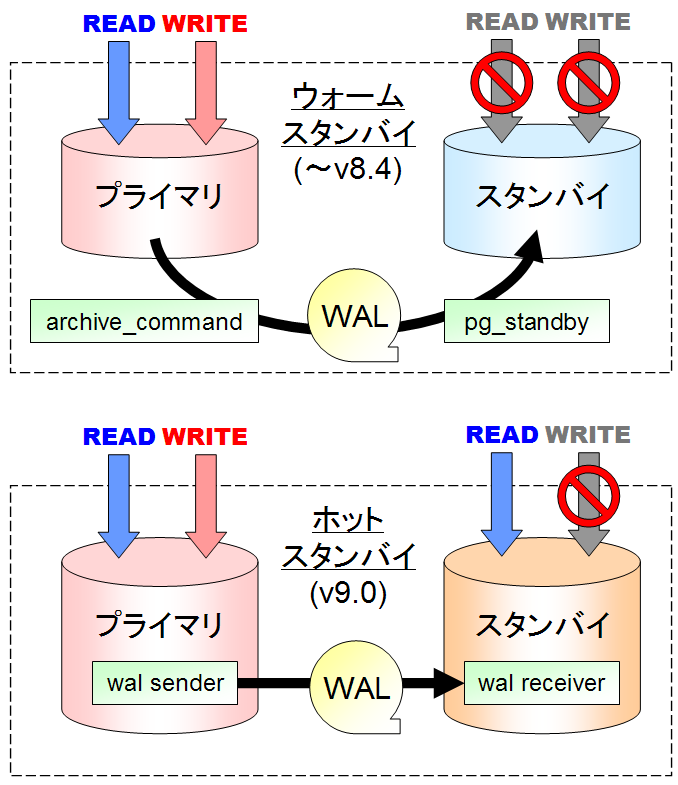
ホット・スタンバイは、以前から要望の多かった機能です。後述のレプリケーション機能と組み合わせることで、複数サーバ間で参照の負荷を分散できるクラスタ構成が使えるようになります。以前のバージョンでは「ウォーム・スタンバイ」として参照も更新もできなかった待機サーバを、参照用として有効活用できるようになります。参照のみと言っても、ソート用の作業ファイルは作成できるため、待機サーバで集計処理や pg_dump などの重い参照クエリを実行するのも良いでしょう。(ただし、一時テーブルは使えません。)
ホット・スタンバイの機能自体は「リカバリ処理中の参照クエリを許す」という一言で説明できるのですが、スタンバイ側で参照中のデータがプライマリで削除された場合の挙動など、細部まで気を配って対応されています。ログシッピングという物理的に完全に同じ状態を作る方式ですので、レプリケーションが完了した領域のデータの構造は完全に一致しています。このため、ユーザから見たデータベースは常に一貫した状態に保たれます。もちろん、プライマリ側で行った VACUUM 処理も転送されますから、スタンバイ側での特別な運用も要りません。
注意が必要なのは、ホット・スタンバイで待機サーバから得られる結果には時間的な遅れがあることです。過去のある時点での一貫性のある結果は取得できますが、ログの適用が遅延していると最新の情報は取得できません。ただし、後述のレプリケーション機能と組み合わせることで、ゼロにはできないものの、遅れは大幅に低減できます。また、リカバリ処理と競合するクエリが長時間続くと、強制的にキャンセルされる場合があります。キャンセルまでの待機時間は調整できますが、時間がかかるクエリをスタンバイ側で実行する場合には気をつけましょう。
参考- Hot Standby (ドキュメント)
- Hot Standby (PostgreSQL Wiki)
ストリーミング・レプリケーション (Streaming Replication)
組み込みのレプリケーションが採用されました。以前のバージョンでもアーカイブログを転送して別サーバで逐次ログを適用する「ウォーム・スタンバイ (warm standby)」が利用できましたが、ストリーミング・レプリケーションには以下の利点があります。
v9.0 のレプリケーションの利点- トランザクションログの転送が、ファイル単位では無く、操作単位で行われるため、遅延が少ない。
- 複数のスタンバイ・サーバへ転送できる。
- スタンバイ・サーバはいつでも追加 / 切り離しでき、追加の際の静止点は不要。
- スタンバイ側で適用済みのトランザクションログを自動的に削除できる。
- PostgreSQL 本体と協調して動作するため、管理に手間がかからない。
注意が必要なのは、遅延が少ないといっても、全く無いわけではないことです。「遅延なし」に転送するオプションは、バージョン 9.1 に向けて開発が進んでいます。完全な一貫性が要求されるシステムでは扱いに注意する必要があります。
- Streaming Replication (ドキュメント)
- Streaming Replication (PostgreSQL Wiki)
既存製品との関係
ホット・スタンバイ + ストリーミング・レプリケーションの組み合わせを使うと、多くの用途で満足できるかと思いますが、それでもまだ足りない点も残っています。
v9.0 のレプリケーションだけでは実現できないこと- 自動的に参照を分散する機能が無い。
- プライマリの故障時に自動的にフェイルオーバーする機能が無い。
- クラスタ間でメジャーバージョンを統一する必要がある。(マイナーバージョンの違いは可)
- データベース全体のみ複製できる。一部だけの複製やデータの分割は不可。
そのため、既存のレプリケーション製品も、用途によっては もしくは v9.0 のレプリケーション機能と組み合わせて、今後も使っていくことになるでしょう。
- pgpool
- 参照を分散する機能は依然として有効です。特に pgpool-II 3.0 では、9.0 のレプリケーションとの連携機能が強化され、レプリケーションは PostgreSQL 本体に任せ、pgpool でクエリ分散やノード管理をするという構成が考えられます。
- Slony-I
- データの一部だけの複製ができるのは Slony-I の利点です。また、SQLベースの複製を行うため、メジャーアップグレードの際に pg_dump の代わりに使えるのは Slony-I だけです。
- PGCluster, PL/Proxy
- データの分割には PGCluster や PL/Proxy のような仕組みが必要です。
- Heartbeat などの監視ミドルウェア
- ダウンタイムを減らすには、フェイルオーバやプライマリへの昇格を自動化する監視ミドルウェアを組み合わせる必要があります。
その他の新機能
9.0 の新機能をカテゴリ別に紹介します。SQL 構文やログ出力機能を中心に改善が進んでいます。
SQL構文の強化
- 排他制約 (Exclusion constraints)
- 排他制約 (EXCLUDE) は、一意性制約 (UNIQUE) を一般化した PostgreSQL の独自機能です。指定した演算子を満たす行は、テーブル中に1行しか存在できません。特に地理情報 (GIS) を扱う場合に、地図上のオブジェクトが重なっていないことを保障するのに便利です。
-- テーブルと同時に定義する。(&& は「重なり」のチェック) =# CREATE TABLE tbl (c circle, EXCLUDE USING gist (c WITH &&)); -- 後付けで定義する。 =# CREATE TABLE tbl (c circle); =# ALTER TABLE tbl ADD EXCLUDE USING gist (c WITH &&);
USING には概ね gist を指定します。 btree の場合は UNIQUE 制約で十分ですし、gin は残念ながら排他制約をサポートしていません。 - ALTER TABLE ... ADD { UNIQUE | PRIMARY KEY } (...) DEFERRABLE
- UNIQUE 制約に DEFERRABLE オプションを指定できるようになりました。一意性の確認はトランザクションのコミット時まで先送りにされるため、一時的に一意性制約の違反になるような変更も許されます。(例: UPDATE ... SET id = id + 1)
- ウィンドウ関数と集約関数の強化
- ウィンドウの定義が拡張され、現在の行 (CURRENT ROW) を基準にした処理
ROWS n PRECEDING/FOLLOWINGが追加され、移動平均の計算ができるようになりました。 以下の例では、±2 の範囲 (5要素) の移動平均を計算しています。=# SELECT n, avg(n) OVER w, first_value(n) OVER w, last_value(n) OVER w FROM generate_series(1,10) AS n WINDOW w AS (ORDER BY n ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING); n | avg | first_value | last_value ----+--------------------+-------------+------------ 1 | 2.0000000000000000 | 1 | 3 2 | 2.5000000000000000 | 1 | 4 3 | 3.0000000000000000 | 1 | 5 4 | 4.0000000000000000 | 2 | 6 5 | 5.0000000000000000 | 3 | 7 6 | 6.0000000000000000 | 4 | 8 7 | 7.0000000000000000 | 5 | 9 8 | 8.0000000000000000 | 6 | 10 9 | 8.5000000000000000 | 7 | 10 10 | 9.0000000000000000 | 8 | 10 (10 rows) - また、集約関数ごとに直接 ORDER BY を指定できるようになりました。
=# SELECT array_agg(i), array_agg(i ORDER BY i) FROM (VALUES (2), (1), (3)) t(i); array_agg | array_agg -----------+----------- {2,1,3} | {1,2,3} (1 row) - CREATE TRIGGER UPDATE OF column / WHEN (...)
- 列更新トリガ (UPDATE OF) では、指定した列を変更の対象に選択した場合にのみトリガ関数が呼ばれます。実際には値が変更されなくても、UPDATE の SET 句に指定された場合には起動されることに注意が必要です。
- 条件付きトリガ (WHEN) では、指定した条件が満たされた場合のみトリガが起動されるため、トリガ内で条件を判定するよりも高速です。よくある使い方として、いずれかの列が変更された際にのみ起動されるようにするためには
new.* IS DISTINCT FROM old.*とするのが良いでしょう。UPDATE OF との違いは、実際に値が変更された場合にのみ起動されることです。 - LISTEN/NOTIFY でメッセージ送受信
- 任意の文字列をメッセージとして送信できるようになりました。これまではイベントが発生したことのみを伝えることしかできませんでしたが、9.0 では何が起きたかも一緒に伝えられます。また、通知データはオンメモリで管理されるよう変更され、性能も向上しました。
[session-1]=# LISTEN foo; LISTEN [session-2]=# NOTIFY foo, 'message'; NOTIFY [session-1]=# ; Asynchronous notification "foo" with payload "message" received from server process with PID 19163.
性能の改善とチューニング
- 64bit版 Windows のサポート
- これまでも 64bit の POSIX 環境はサポートされてきましたが、やっと Windows でも 64bit 版をサポートしました。大容量のメモリを活かすことができます。
- オプティマイザ:利用されない JOIN の削除
- JOIN されるテーブルがあっても、データを取得しなければ JOIN 対象から外す最適化が行われるようになりました。特に LEFT JOIN を利用するビューで役立ちます。以下の例では、tbl_right のスキャンを省略できていることがわかります。
=# CREATE TABLE tbl_left (id integer, a text); =# CREATE TABLE tbl_right (id_ref integer UNIQUE, b text); =# CREATE VIEW tbl AS SELECT * FROM tbl_left LEFT JOIN tbl_right ON id = id_ref; =# EXPLAIN SELECT id, a FROM tbl; => Seq Scan on tbl_left - VACUUM FULL の高速化
- VACUUM FULL のアルゴリズムが改められ、ゴミが多い場合の処理が大幅に高速化されました。一方、ゴミが少ない場合にはむしろ遅くなっているので、「毎晩 vacuumdb --full」するような運用は改める必要があります。また、処理中に元のテーブルと同じサイズの一時ディスク領域が必要になったため、ディスクフル間近の場合は実行できなくなりました。
- ALTER TABLE ... ALTER COLUMN ... SET (n_distinct)
- 列ごとのカーディナリティ統計情報を強制的に固定値に設定できるようになりました。PostgreSQL の統計情報収集ロジックが上手く働かない場合のチューニング手段です。
- ALTER TABLE ... ALTER COLUMN ... SET STORAGE MAIN
- 列ごとのストレージ・オプション MAIN の効果が変更され、その列が TOAST 領域に追い出されるのを防止できるようになりました。行サイズが 2KB 以上になる場合のチューニング手段です。
ログとプロファイラ
- EXPLAIN ( format { text | xml | json | yaml } )
- EXPLAIN の出力を、これまでのテキスト形式に加えて、XML, JSON, YAML 形式で取得できるようになりました。人間が読みやすいのはテキスト形式ですが、もし実行計画を画像として表示するようなツールを作る場合には、これらの構造化された書式が便利でしょう。
- EXPLAIN (ANALYZE, BUFFERS)
- EXPLAIN ANALYZE で実際の動作を解析する際に、バッファアクセス状況を追加で取得できるようになりました。共有バッファ、一時テーブル、ソート領域のキャッシュヒット数や I/O 回数が表示されます。スロークエリの原因が、I/O 回数なのか、メモリアクセス回数なのか、ソート用メモリ不足なのか、といった解析に役立ちます。
- pg_stat_statements にバッファアクセス状況の追加
- 上記の EXPLAIN BUFFERS 相当の情報を pg_stat_statements でも収集できます。スロークエリを見つけると同時に、そのクエリがなぜ遅いのかを解析できます。
- 一意性制約の違反時に列の値を出力
- 一意性制約のある列の変更時やユニーク・インデックスの作成時に、制約違反があった列の値をログに出力するようになりました。
=# UPDATE tbl SET id = 1 WHERE id = 2; ERROR: duplicate key value violates unique constraint "tbl_pkey" DETAIL: Key (id)=(1) already exists.
- クライアント・アプリケーション名の表示
- 設定パラメータ application_name を使ってクライアント・アプリケーション名を表示またはロギングできるようになりました。libpq で接続を行うアプリケーションでは、環境変数
PGAPPNAMEを使って初期値を設定できます。この機能はセキュリティ用途ではなく、単にプロセス一覧やログを読みやすくする機能です。アプリケーション名の指定の強制や詐称の防止、特定のアプリケーションの拒否といったことはできません。
セキュリティとアクセス管理
- ALTER LARGE OBJECT: ラージオブジェクトのアクセス制御
- ラージオブジェクトに所有権と読み書きのアクセス制御ができるようになりました。そのための構文 ALTER LARGE OBJECT, GRANT/REVOKE LARGE OBJECT も追加されています。以前のバージョンではアクセス管理機能が無いばかりに bytea で代用せざるを得ない場合がありましたが、9.0 ではラージオブジェクトでも遜色の無いアクセス管理ができます。
- 権限管理機能の強化
- "GRANT/REVOKE ON ALL objects IN SCHEMA" では指定したスキーマに含まれるオブジェクトのアクセス権を一括で変更できます。また、"ALTER DEFAULT PRIVILEGES" 構文で将来に作成されるオブジェクトに対するアクセス権限のデフォルト値を設定できるようになりました。
- passwordcheck モジュールの導入
- 推測されにくいパスワードのみを許可できるフィルタが追加されました。デフォルトの設定では 8 文字以上かつアルファベットと非アルファベットの組み合わせからなるパスワードだけを許します。
便利な機能
- DO 'code'
- 関数を作成せずにインラインで手続き言語 (PL/pgSQL 等) を実行できます。クエリの結果を元に DDL を発行するような場合に、スクリプトファイルを作る代わりに使えます。
- pgbench -j スレッド数
- pgbench がマルチスレッド化され、CPUが複数ある環境でも十分な負荷をかけられるようになりました。これまでは pgbench 自体がボトルネックになり、サーバの性能を引き出せない場合がありました。スレッド数は pgbench を実行するマシンの CPU 数程度に設定すると良いようです。
これ以外の変更は「その他の機能」に一覧があります。
まとめ
PostgreSQL 9.0 は、レプリケーションを始め、機能強化が著しいリリースになりました。ぜひ、高性能、高機能、高信頼な最新の PostgreSQL を体験してください!
| リリース名 | リリース日 |
|---|---|
| 9.0 Beta 1 | 2010-05-03 |
| 9.0 Beta 2 | 2010-06-04 |
| 9.0 Beta 3 | 2010-07-12 |
| 9.0 Beta 4 | 2010-07-30 |
| 9.0 RC 1 | 2010-08-30 |
| 9.0.0 | 2010-09-20 |
外部リンク
PostgreSQL 9.0 に関する情報の収集には、以下のサイトが参考になります。
- 9.0 プレスキット
- PostgreSQL 9.0.0 リリースノート (ドキュメント)
- 機能マトリックス
- What's new in PostgreSQL 9.0 (PostgreSQL Wiki)
- PostgreSQL 9.0 に関する技術情報 (SRA OSS, Inc.)
- "PostgreSQL最新情報 8.4 から 9.0 へ" (PDF), 高塚遙, オープンソースカンファレンス 2010 Tokyo/Spring
- PostgreSQL 9.0 アップデート:ホットスタンバイがやってきた!, 板垣貴裕, オープンソースカンファレンス 2010 Tokyo/Fall