
PostgreSQL の構造とソースツリー(1)
SRA OSS, Inc.日本支社 石井達夫
この記事では、PostgreSQL の全体構造と、ソースツリーの概要を説明します。 前提としているバージョンは PostgreSQL 9.1.x です。 ほかのバージョンでは、多少細部が違っているかも知れません。
この記事は、2005年に発行された技術評論社の「WEB+DB PRESS Vol.26」 に掲載された記事をベースに、PostgreSQL 9.1の現状に合わせて加筆訂正したものです。
PostgreSQL の利用形態
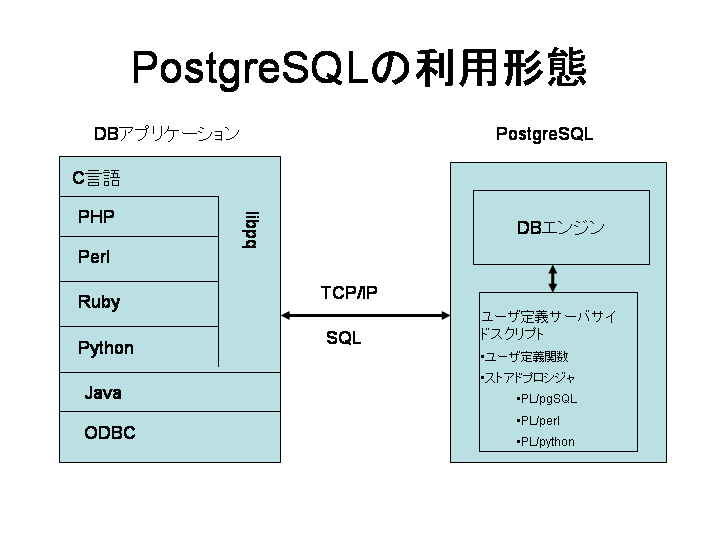
PostgreSQL はいわゆるクライアント/サーバ型のアーキテクチャを採用しています。 PostgreSQL を利用するアプリケーションは、まず定められたプロトコルにしたがい、INET または Unix ドメインソケットを通じて PostgreSQL のサーバに接続しなければなりません。
「スタンドアローン・バックエンド」という利用形態もあり、PostgreSQL のデータベースエンジンを直接起動することも可能ですが、データベース・クラスタ (他のデータベースでは「インスタンス」と呼ばれるものに相当) の初期化か、緊急メインテナンス時にしか使用されないので、普通はクライアント/サーバで PostgreSQL を利用すると思ってかまいせん。
PostgreSQLでは、クライアントをフロントエンド (frontend)、サーバをバックエンド (backend) と呼びます。 バックエンドは複数のプロセスから構成されていますが、それについてはこの後で説明します。
フロントエンドとバックエンドの通信プロトコルは、PostgreSQL のドキュメント「フロントエンド/バックエンドプロトコル」に詳しく書かれています。 基本的には問い合わせ (SQL 文) をフロントエンドからバックエンドに送信し、その結果が複数のパケットに分かれてバックエンドからフロントエンドに返ってくるような仕掛けになっています。
接続の開始処理やエラー処理など、いろいろなことをやらなければならないので、PostgreSQL のプロトコル処理は結構複雑になります。 これをすべてのフロントエンドで実装するのは大変なので、C 言語で書かれた libpq という共通ライブラリが提供されており、これを使って簡単にバックエンドとの通信を行うことができます。 PostgreSQL は Perl や PHP など、C 言語以外のプログラミング言語をサポートしていますが、これらは内部で libpq を呼び出しています。
libpq を使わずに独自に PostgreSQL との通信を行うライブラリもあります。 代表的なものが Java で、PostgreSQL 用の JDBC ドライバは、独自にネットワーク通信を行うことにより、libpq に頼ることなく実装されています。
一方バックエンドの方は、中心となるのがデータベース処理を実行するデータベースエンジンです。 データベースエンジンにはユーザが作成したアプリケーションを実行する機能があります。 この機能を使って、ユーザは柔軟に PostgreSQL の機能を拡張できます。 良く利用されるのは、ほかのデータベースで言うところの「ストアドプロシジャ」で、PostgreSQL ではユーザ定義関数と呼びます。言語別に以下のようなものが利用できます。
| 言語 | ユーザ定義関数処理系 |
|---|---|
| C | C 関数 |
| SQL | SQL 関数 |
| Oracle の PL/SQL に似た独自言語 | PL/pgSQL |
| Perl | PL/Perl |
| Python | PL/Python |
PostgreSQL では、ユーザが独自にユーザ定義関数の処理系を定義することができます。 そこで各種言語用のサーバサイドスクリプトがサードパーティーによって提供されています。 主なものとしては、Ruby, Java, PHP などがあります。
PostgreSQL の構造
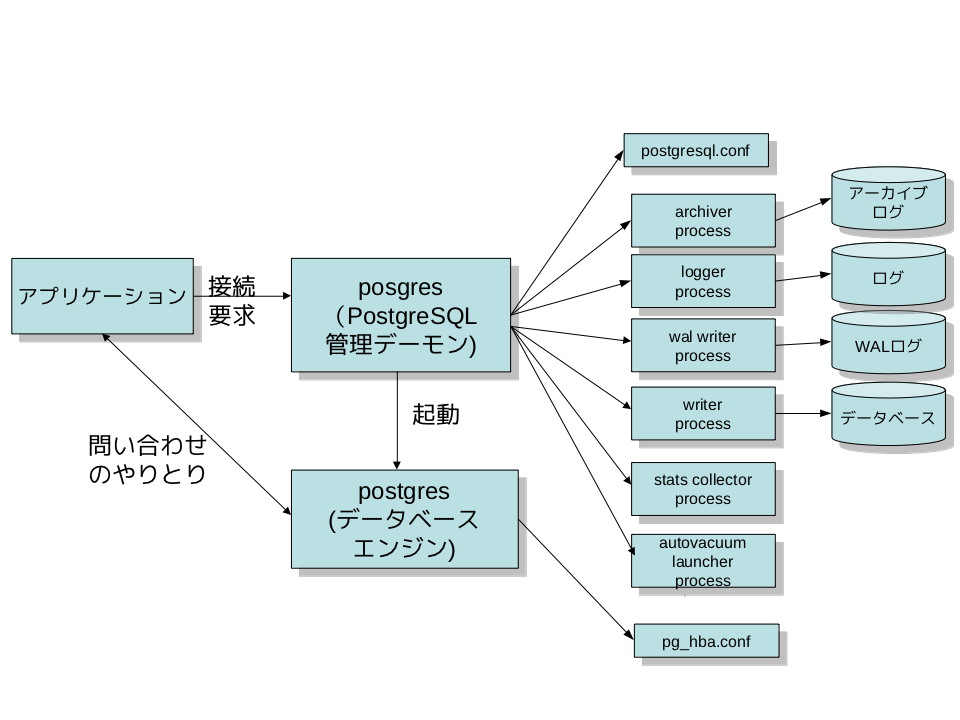
それでは、もう少し詳しく PostgreSQL の構造を見てみましょう。
バックエンド側はいくつかのプロセスから構成されています。
postgres (常駐プロセス)
バックエンドを管理する常駐プロセスです。 "postmaster" とも呼ばれます。 デフォルトでは postgres は UNIX ドメインソケットと TCP/IP の 5432 番のポートを listen しており、フロントエンドがここに接続するのを待ち受けています (Windows など、一部のプラットフォームでは TCP/IP のみ)。 待ち受けるポート番号は PostgreSQL のメイン設定ファイルである postgresql.conf によって変えられます。
フロントエンドが postgres に接続すると fork(2) によって子プロセスを生成します。fork(2) を持たない Windows プロットフォームでは、 CreateProcess() を使って新たにプロセスを生成します。 この場合は fork(2) と違って自動的に親プロセスのデータを引継げないので、共有メモリを利用して親プロセスのデータを引継ぎます。
postgres (子プロセス)
子プロセスでは、まずセキュリティポリシーファイルである pg_hba.conf によって接続の可否がチェックされます。 ポリシーにより、特定の IP アドレスやネットワークからの接続を拒否したり、特定ユーザやデータベースのみ接続を許可することもできます。
postgres はフロントエンドからの問い合わせを受け取ってはデータベースを検索して結果を返したり、データベースの更新を行ったりします。 更新データは同時にトラザンクションログ (PostgreSQL では WAL ログと呼びます) と呼ばれる特別なファイルに記録され、主に一停電などでコンピュータがダウンし、再起動後データベースの不整合が起きた際にはリカバリ処理を行うために使用されます。 更に適当なタイミングでアーカイブログ領域に移され、リカバリ処理に備えて保存が可能になっています。 また、PostgreSQL 9.0 以降では、WAL ログを他の PostgreSQL に転送することによって、リアルタイムにデータベースの複製を作成する「レプリケーション」機能が使えるようになっています。 これらの処理の一部は次に説明する別プロセスが実行します。
その他のプロセス
postgres 以外にいくつか補助プロセスがあります。 これらはすべて常駐プロセスの postgres から起動されるプロセスです。
ライター・プロセス
「ライター・プロセス」(writer process) は、共有メモリ上のバッファを最適なタイミングでハードディスクに書出します。 これによって、チェックポイントの際に大量のディスク書き込みが起きてパフォーマンスが劣化することを防ぎ、安定したパフォーマンスが維持できます。 バックグラウンド・ライター・プロセスは一度起動されたら以後常駐しますが、 ずっと動き続けているわけではなく、postgresql.conf の bgwriter_delay で規定される時間 (デフォルトでは 200 ミリ秒) 休止してはまた動くという動作を繰り返します。
ライタープロセスのもう一つの重要な仕事は、チェックポイント処理を定期的に実行することです。
チェックポイントは、定期的に共有メモリ上のバッファの内容をデータベースファイルに書出し、メモリとディスクの状態を一致させます。 これによって、システムがクラッシュした際に、WAL からのリカバリに要する時間を短縮します。 また、WAL が無限に増えるのを防ぎます。
チェックポイントは postgresql.conf の checkpoint_segments、checkpoint_timeout で指定されるタイミングで自動的に実行されます。
WAL ライタープロセス
WAL ライタープロセス (WAL writer process) は、共有メモリ上の WAL バッファを最適なタイミングでハードディスクに書出します。 これによって、バックエンドプロセスが自ら WAL バッファの書き出しを行なう負担を軽減し、パフォーマンスを向上させます。 また、非同期コミットが有効な場合、一定時間のうちに WAL バッファの内容が WAL ログに書かれることを保証する役割もあります。
アーカイバープロセス
アーカイバープロセスは、WAL ログをアーカイブログに移します。 ベースバックアップとアーカイブログを保存しておけば、データベースを格納したディスクが完全に破壊されても直近の状態に戻ることができます。
統計情報収集プロセス
統計情報収集プロセス (stats collector process) は、テーブルへのアクセス回数やディスクへのアクセス回数などの情報を収集するプロセスです。 ここで収集された情報は、autovacuum が利用する他、データベースの管理者が参照してデータベースの管理に役立てるためます。
ロガープロセス
ロガープロセス (logger process) は、PostgreSQL の活動状態を出力するログ (WAL のことではありません) をファイルに書出したり、指定された間隔でローテートさせる処理を行ないます。
autovacuum 起動プロセス
autovacuum 起動プロセス (autovacuum launcher process) は、常駐 postgres プロセスに依頼する形で、自動 VACUUM プロセスを間接的に起動します。 自分自身では自動 VACUUM プロセスの起動は行ないません。これはより信頼性を向上させるためです。
自動 VACUUM プロセス
自動 VACUUM プロセス (autovacuum worker process) は、自動 VACUUM を実際に実行します。 複数プロセスが並行して自動 VACUUM を行う場合もあります。
wal sender / wal receiver
wal sender プロセスは、wal receiver プロセスとともに、PostgreSQL のレプリケーション (streaming replication) を実行するためのプロセスです。 wal sender プロセスは、WAL をネットワーク経由で送信し、別な PostgreSQL インスタンスの wal receiver プロセスがそれを受診します。 wal receiver プロセスが動く PostgreSQL (「スタンバイ」と呼ばれます) は、WAL を自分の DB に適用にすることにより、送信元の PostgreSQL (「プライマリ」と呼ばれます) とそっくり同じデータベースを作成することができます。
バックエンドの処理の流れ
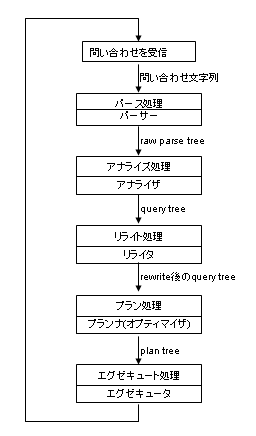
次に、データベースエンジンである postgres の子プロセスの処理の概要を見てみましょう。 以後このプロセスをバックエンドプロセスないし、単にバックエンドと呼ぶことにします。 なお、バックエンドのメイン関数は PostgresMain (tcop/postgres.c) です。
-
フロントエンドから送られてきた問い合わせ (SQL 文) を受信
-
SQL 文は単なる文字列なので、そのままではコンピュータ処理には向いていません。 そこで内部的に扱いやすいパースツリー (parse tree) の形に変換します。 ここでの処理は「パース処理」と呼ばれ、パース処理を行うモジュールをパーサ (parser) と呼びます。
この段階では、文字通り問い合わせ文字列から得られる情報のみを使用します。 したがって、文法的に間違いのない限り、存在しないテーブルを SELECT しようとしてもエラーになりません。 この段階のパースツリーはローパースツーリー (raw parse tree) とも呼ばれます。 パース処理のエントリポイントは raw_parser (parser/parser.c) です。
-
パースツリーを解析し、クエリツリー (query tree) に変換します。 このとき、データベースをアクセスして指定されたテーブルが実際に存在するかどうかチェックし、存在すればテーブル名から OID に変換するなどの処理が行われます。 ここでの処理はアナライズ処理と呼ばれ、アナライズ処理を行うモジュールをアナライザ (analyzer) と呼びます。 なお、PostgreSQL のソースコードでパースツリーと言えば、クエリツリーのことを指すことが多いようです。 アナライズ処理のエントリポイントは parse_analyze (parser/analyze.c) です。
-
PostgreSQL では、VIEW や RULE をクエリを書き換えることによって実装しています。 もし必要ならばこの段階でクエリを書き換えます。 ここでの処理はリライト処理と呼ばれ、リライト処理を行うモジュールをリライタ (rewriter) と呼びます。 リライト処理のエントリポイントは QueryRewrite (rewrite/rewriteHandler.c) です。
-
クエリツリーを解析し、実際に問い合わせを実行するためのプランツリー (plan tree) を作成します。 ここでの処理は「プラン処理」と呼ばれますが、もっとも実行時間が短くて済みそうなプランツリーを作成することが非常に大切です。 そのため、この処理はクエリオプティマイズ (query optimize: 最適化) ないし単にオプティマイズと呼ばれることもあります。 こうした処理を行うモジュールをクエリオプティマイザ (query optimizer) ないし、単にオプティマイザと呼びます。(あるいはプランナ (planner) と呼ぶこともあります)。 プラン処理のエントリポイントは standard_planner (optimizer/plan/planner.c) です。
-
プランツリーに従い、問い合わせを実行します。 ここでの処理はエグゼキュート処理と呼ばれ、エグゼキュート処理を行うモジュールをエグゼキュータ (executor) と呼びます。 エグゼキュータ処理のエントリポイントは ExecutorRun (executor/execMain.c) です。
-
実行結果をフロントエンドに送信します。
-
再び 1) に戻ります。
(2011年11月15日公開)