
3.変換の実際
では、これらのSQL/XML機能を使ってリレーショナルデータからXMLデータを生成するシナリオを考えましょう。
ブラウザで表示できるHTMLは、開始タグと終了タグの対応をきちんと取ることによってXMLとも見なせます(XMLとしての形式を持ったHTMLはXHTMLと呼ばれます)。それで、ここでは、実行結果をすぐに確認できるHTML(XHTML)を生成することにします。
さて、生成元となるリレーショナルデータとしては、引き続き、第3回から使っているmeiboテーブルを使います。meiboテーブルはリレーショナルデータとXMLデータの両方を含むハイブリッドなテーブルですが、今回はリレーショナルデータの部分であるname列とemail列を使います。そこから値を取り出し、SQL/XML機能を使って要素生成・ツリー構築を行い、ブラウザで表示可能な一覧表となるHTMLデータを出力します。
全体の流れを図にすると以下のようになります。
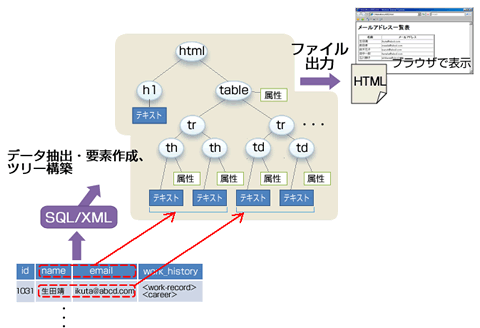
- 図1 SQL/XMLの機能
| id | name | Department | age | work_history | |
|---|---|---|---|---|---|
| 1031 | 生田靖 | IT事業統括部 | 45 | ikuta@abcd.com | (省略) |
| 1088 | 前田孝 | ネットワーク管理課 | 41 | maeda@abcd.com | (省略) |
| 1101 | 鈴木花子 | 開発一課 | 33 | suzuki@abcd.com | (省略) |
| 1103 | 田中一郎 | 開発二課 | 32 | tanaka@abcd.com | (省略) |
| 1076 | 石川順子 | 開発一課 | 23 | ishikawa@abcd.com | (省略) |
3.1 今回生成したいHTMLの内容
図1で記したように、今回のSQL/XML利用シナリオでは、ブラウザで表示可能な一覧表として、最終的に次のようなHTMLを作成することを目的とします。
-
<html> <h1>メールアドレス一覧表</h1> <table border="5" width="70%"> <tr><th>名前</th><th>メールアドレス</th></tr> <tr><td width="30%">生田靖</td><td width="70%">ikuta@abcd.com</td></tr> <tr><td width="30%">前田孝</td><td width="70%">maeda@abcd.com</td></tr> <tr><td width="30%">鈴木花子</td><td width="70%">suzuki@abcd.com</td></tr> <tr><td width="30%">田中一郎</td><td width="70%">tanaka@abcd.com</td></tr> <tr><td width="30%">石川順子</td><td width="70%">ishikawa@abcd.com</td></tr> </table></html>
PostgreSQLから取り出した名前とメールアドレスのデータは、表を表す<table>要素の内側で表のセルを表す<td>要素の内容として埋め込まれています。つまり、リレーショナルデータからname列の内容を<td>~</td>タグの内側に、email列の内容をもう一つの<td>~</td>タグの内側に参照しながら埋め込んでいけばよいわけです。
3.2 SQL/XMLを使ったSELECT文の解析
ではここで、前回の記事までで作成したmeiboテーブルからname列とemail列を取り出し、前述のHTMLを作成する実際のSELECT文を提示し、SQL/XMLの働きをひとつひとつ説明します。
SELECT文:(説明のため行番号を振ってあります。)
(1) select xmlelement(name html,
(2) xmlelement(name h1,'メールアドレス一覧表'),
(3) xmlelement(name table,
(4) xmlattributes('5' as border, '70%' as width),
(5) xmlelement(name tr, xmlelement(name th,'名前'),
(6) xmlelement(name th,'メールアドレス')),
(7) (select xmlagg
(8) xmlelement(name tr,
(9) xmlelement(name td,xmlattributes('30%' as width), name),
(10) xmlelement(name td,xmlattributes('70%' as width), email)
(11) )) from meibo)));
この中で使用されているSQL/XML関数の働きを順を追って説明します。
3.3.1 HTMLデータの最上位要素”html”の生成
1行目:(1) select xmlelement(name html,
SELECT文の中にXML要素を生成するxmlelement関数を記述していますが、ここでは生成するXML要素の名前を「html」と指定しています。
xmlelement 関数の基本構文は以下の通りです。
xmlelement(name name
[, xmlattributes(value [AS attname] [, ... ])]
[, content, ...])
nameというキーワードのあとに生成したい要素名を指定します。属性を付与する場合はxmlattributes()を使って属性を指定します(属性の書き方は後述)。値(content)は、属性(attributes)の後にカンマ「 , 」で区切って入力します。contentには値として、列参照、テキストのほか、コメントノードを生成するxmlcomment関数や、要素を生成するxmlelement関数(入れ子=階層構造になる)、一連の要素をまとめて作成するxmlforest関数などを記述することができます。
3.3.2 見出し”h1”の生成
2行目:(2) xmlelement(name h1,'メールアドレス一覧表'),
(2)は、(1)の xmlelement の中で再度 xmlelement が使われています。こうすることで、html要素の下位要素としてh1要素が生成されるという階層関係を表現した記述となっているのです。
さて、ここでの指定では、 xmlelement 関数により、”<h1>メールアドレス一覧表</h1>” という値が返されます。「メールアドレス一覧表」というシングルクォーテーション「'」で括った文字がそのまま要素の値になりますが、既存のテーブルの列を参照して値としたい場合は、列名をそのまま指定するか、ダブルクォーテーション「”」で括ります。したがって、誤って「”メールアドレス一覧表”」と記述すると、存在しないメールアドレス一覧表列を探しに行ってしまい、「そのような列は存在しません」というエラーになりますので注意が必要です。
3.3.3 表の生成(表全体と表見出し)
3行目~6行目:
(3) xmlelement(name table,
(4) xmlattributes('5' as border, '70%' as width),
(5) xmlelement(name tr, xmlelement(name th,'名前'),
(6) xmlelement(name th,'メールアドレス')),
(3)と(4)ではtable要素を生成し、xmlattributes関数を使ってtable要素に属性をつけています。border="5" width=”70%” という2つの属性が生成されます。
(5)と(6)ではTR要素の内側にTH要素を2つ作っています。TH要素は表の見出しになる要素です。ここで(3)~(6)までのSQL/XML関数で生成されるHTMLデータは以下の通りです。
<html> <h1>メールアドレス一覧表</h1> <table border="5" width="70%"> <tr><th>名前</th><th>メールアドレス</th></tr>
これでページのタイトルと表のタイトルができました。ここまでの指定では、タイトルや表見出しなどの固定的データを生成しましたが、次に、表の中にリレーショナルデータを利用してその内容に合わせたデータを埋め込む部分に入ります。
3.3.4 表の内容の生成(RDBに格納されたデータを用いて)
7行目~11行目:
(7) (select xmlagg(
(8) xmlelement(name tr,
(9) xmlelement(name td,xmlattributes('30%' as width), name),
(10) xmlelement(name td,xmlattributes('70%' as width), email)
(11) )) from meibo)));
(7)から(11)では、(1)で指定したSELECT文の中でもう一つのSELECT文を指定しています。この部分では、3行目で名前を指定したtable要素の中に下位要素としてTR要素とTD要素を生成します。
TD要素は、その値としてnameとemailを指定していますが、これは列参照ですので、name列とemail列の内容を取得して値として埋め込まれます。これに加え、TD要素にはattributes関数でwidth属性を付与しています。これら並行する2つのTD要素は、8行目で生成しているTR要素の内側に生成されます。
ところで、7行目では括弧の内側にある第二のSELECT文(スカラー副問い合わせと呼ばれる)でxmlagg関数を使っています。これは8行目~10行目で作成されるXML要素を“集約”するための関数です。これを使う必要があるのは、式の部分でSELECT文を書くスカラー副問い合わせの戻り値は1行しか許されていないというSQLの制約があるためです(Postgres8.3.7文書4.2.9スカラ副問い合わせを参照)。(8)~(10)の式では、1行以上のXML要素を返すので、そのままではエラーになってしまいます。それで、xmlagg関数を用いて1行に集約する必要があるのです。(xmlaggが複数行を集約する働きについてはすぐあとの3.3.5で説明します)
(11)にサブクエリーのFROM句がありますが、meiboテーブル全体を参照していますので、meiboテーブルのname列とemail列すべての内容が各td要素に埋め込まれ、さらにtd要素を束ねるtr要素と一緒に、上の親要素であるtable要素の内側に埋め込まれます。
3.3.5 xmlagg関数の役割
xmlagg関数は複数行にわたるXML要素をまとめて1行にするための関数です。xmlagg関数の働きを確認するため以下に例を2つ挙げます。
例1 email列のデータを取り出してXML要素を作成する[xmlagg未使用]:
testdb=# select xmlelement(name a,email) from meibo;
xmlelement
--------------------------
<a>ikuta@abcd.com</a>
<a>maeda@abcd.com</a>
<a>suzuki@abcd.com</a>
<a>tanaka@abcd.com</a>
<a>ishikawa@abcd.com</a>
(5 rows)
最後に(5 rows)とあるように、5行のデータとして結果が返っています。これはスカラー副問い合わせとしては使えません。そこでxmlagg関数を使うと以下のようなデータとして結果が返ってきます。
例2 email列のデータを取り出してXML要素を作成する[xmlaggを使用]:
testdb=# select xmlagg(xmlelement(name a,email)) from meibo;
xmlagg
------------------------------------------------------------------
<a>ikuta@abcd.com</a><a>maeda@abcd.com</a><a>suzuki@abcd.com</a><a>tanaka@abcd.com</a><a>ishikawa@abcd.com</a>
(1 row)
最後に (1 row) とあるように、これは1行のデータです。このような形にしてスカラー副問い合わせを使えるようにするのがxmlagg関数の役割です。
4. SQL/XMLの実行および結果の確認
では、実際にSQL/XMLを使った照会を実行し、meiboテーブルからHTMLを生成しましょう。
4.1 データベースへの接続
まず、データベース(testdb)への接続を行います。
C:\Program Files\PostgreSQL\8.3\bin>psql testdb postgres
ここで、いつものようにパスワードを聞かれるので、パスワードを入力します。
4.2 HTMLファイル生成のための準備作業~ヘッダ・フッタ出力の抑止と出力ファイル指定~
結果をHTMLファイルとして書き出すために、第4回と同じようにヘッダ、フッタの非表示オプションと出力するファイルを指定しておきます。(その前に、通常通りスタートメニューからPostgreSQL8.3用のコマンドプロンプトを開き、psqlでtestdbに接続します)
ヘッダー/フッター非表示オプションの指定法:testdb=# \t Showing only tuples.
(非表示モードを解除するときはもう一度\tを実行します。)
ファイルへの出力指定:testdb=# \o 'C:/data/result002.html'
(ファイルへの出力を解除するときは、ファイル指定なしで\oのみ実行します。)
4.3 SELECT文の実行
「3.2 SQL/XMLを使ったSELECT文の解析」で説明したSELECT文を実行します。
=# select xmlelement(name html,
(# xmlelement(name h1,'メールアドレス一覧表'),
(# xmlelement(name table,
(# xmlattributes('5' as border, '70%' as width),
(# xmlelement(name tr, xmlelement(name th,'名前'),
(# xmlelement(name th,'メールアドレス')),
(# (select xmlagg(
(# xmlelement(name tr,
(# xmlelement(name td,xmlattributes('30%' as width), name),
(# xmlelement(name td,xmlattributes('70%' as width), email)
(# )) from meibo)));
この結果、HTMLデータが生成されます。
4.4 生成されたHTMLの表示
ファイルとして出力されたresult002.htmlをブラウザで開いてみましょう。
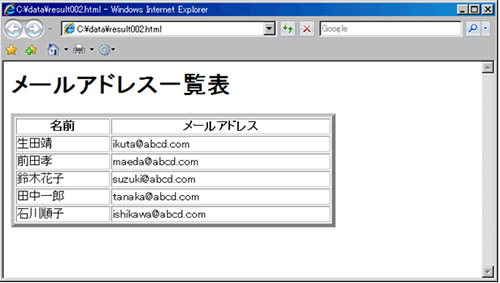
いかがでしょうか。基本的には、SQLの照会結果をxmlelement関数などで生成した要素の中に値として埋め込む方式で、簡単にXMLが作れます。高度な構造変換についてはXSLTを利用した方が自由自在ですが、簡単なものならばSQL/XMLの機能で十分使えそうです。
5.まとめ
データ交換でのXMLの利用が定着した一方、データベースとしては既存のリレーショナルデータをそのまま利用したい、あるいは利用しなければならないというケースは多いと思います。そのような時に、今回ご紹介したSQL/XML機能は大変有用です。ここの機能を使いこなせるようになると、RDBによる確立されたデータ格納手法とXMLによる標準的なデータ交換手段の2つを手に入れることができることになります。これは、リレーショナルとXMLの2つをサポートしているPostgreSQLの大きな強みです。
次回は、XMLを利用する際に必ず出てくる「XMLスキーマ」について紹介し、スキーマによるデータ検証とPostgreSQLとの連携について説明します。