
pgpool-II 3.4の新機能
SRA OSS, Inc. 日本支社
石井 達夫
はじめに
本記事は2014年のPostgreSQL Advent Calendar の 12/17 の記事です。2014年11月7日にリリースされた pgpool-II 3.4の新機能を紹介します。
pgpool-IIとは
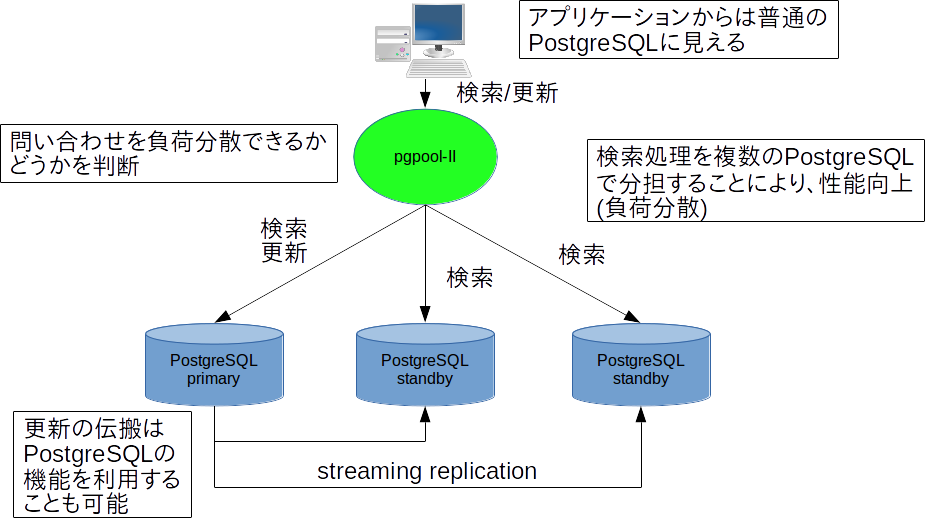
pgpool-IIは、複数のPostgreSQLを使ったクラスタシステムを構築できるミドルウェアです。pgpool-IIは、PostgreSQLクライアントと、複数のPostgreSQLの間に割り込む形でproxyのように動作します。既存のPostgreSQLアプリケーションを、ほとんど変更することなく利用することができます。
もっとも多いpgpool-IIの使い方としては、PostgreSQLを複数台使ったストリーミングレプリケーション構成によるクラスタの管理サーバとして使用するものです。以下のような機能が利用できます。
- PostgreSQLの死活監視。ダウンしたPostgreSQLを検知して、クラスタ構成から切り離すことにより(フェイルオーバ)、クラスタとしての運用を継続します。
- PostgreSQLプライマリサーバがダウンした際に、他のスタンバイサーバを自動昇格させることができます。
- 検索負荷分散。検索クエリを自動的にPostgreSQLサーバに振り分けることにより、検索性能を向上させます。
pgpool-IIはオープンソースとして提供されており、どなたでも自由に利用することができます。活発に開発が行われており、PostgreSQL同様、年に1度のメジャーリリース、年に数回のマイナーリリースがあります。
pgpool-II 3.4の新機能その1: PostgreSQL 9.4対応
この記事を皆様が目にする頃には、PostgreSQL 9.4がリリースされていると思いますが、pgpool-II 3.4はすでにPostgreSQL 9.4に対応済みです。pgpool-IIは内部にPostgreSQLから移植したSQLパーサを持っており、これが9.4対応となりました。たとえば、ALTER SYSTEM, REFRESH MATERIALIZED VIEW CONCURRENTLY, SELECT ... WITH ORDINALITY, SELECT ... FOR UPDATE NOWAIT といった新しい構文に対応します。
また、PostgreSQL 9.4では、to_regclassという新しい関数が追加されました。この関数はテーブル名を渡すとOID(オブジェクト識別子)を返す関数で、存在しないテーブルを渡されてもエラーにならないところが従来の関数(regclass)と異なります。pgpool-IIではクエリを解析する際にregclass相当の機能が必要だったのですが、存在しないテーブルを渡してエラーを起こされては困るので、今までは自前のC関数を用意していました。pgpool-II 3.4 ではto_regclass関数が存在する場合には自動的にこの関数を利用するので、自前の関数をインストールする必要がなくなりました。
pgpool-II 3.4の新機能その2: 性能チューニングのパラメータ追加
pgpool-IIの性能をチューニングするパラメータ追加されました。
check_unlogged_table をoffにすると、unloggedテーブルかどうかのチェックを省略します。unloggedテーブルを利用していない場合には、pgpool-IIがunloggedテーブルかどうかを確認するために発行する無駄な問い合わせが発行されるのを防ぐことができます。
connect_timeout は、pgpool-IIがPostgreSQLに接続する際のタイムアウトを指定します。クラウド環境などで、ネットワークが不安定になることがある場合に、connectシステムコールのタイムアウトにより、頻繁にフェイルオーバが起こるのを防ぎます。
listen_backlog_multiplier は、クライアントからの接続を待ち受けるためのカーネル内のリクエストキュー(listenキュー)の長さを指定します。listenキューの長さが短すぎると、TCP/IPのリトライにより、クライアントからの接続に非常に時間がかかり、極端にパフォーマンスが低下します。この現象の詳細については、別の記事を参照してください。
pgpool-II 3.4の新機能その3: きめ細かいログ設定が可能に
ログの出力設定を行う log_error_verbosity, client_min_messages, log_min_messages が導入されました。ご存知の方も多いかと思いますが、これはPostgreSQLの設定項目とまったく名前で、役割も同じです。
実は今回これらの機能が実現できたのは、PostgreSQLのログモジュールが導入されたからです。PostgreSQLでは、ログモジュールと例外処理が一体になっており、今回pgpool-IIにも例外処理機構が実装されたことになります。ユーザからは直接見えないところですが、例外処理の導入によってコードがシンプルになり、信頼性もあがるというメリットが出てきました。
pgpool-II 3.4の新機能その4: 検索負荷分散のきめ細やかな制御
pgpool-IIは、検索処理を複数のPostgreSQLにセッションに割り当てて実行し、全体として検索性能を上げる機能をもっており、これを「負荷分散」と呼んでいます。更に、PostgreSQLサーバごとに負荷のかけ具合を調整することができます。具体的には、設定ファイルにPostgreSQLごとの相対的な「重み」を数字で指定することができます。
たとえばとかく負荷が高くなりがちなプライマリサーバの重みを0にしておくと、検索処理はスタンバイサーバでのみ実行されるので、プライマリサーバの負荷が下がり、更新性能を上げることができます。
しかし、一方で「重み」が物理的なPostgreSQLのサーバ(pgpool-IIではDBノードIDという番号で識別します)に固定的にバインドされているため、もしフェイルオーバ・昇格によってプライマリサーバのノードIDが変わると、プライマリサーバに割り当てられた重みが変わってしまう、ということになります。
また、あるスタンバイサーバを重い検索処理専用にしたい場合、従来はpgpool-II経由だとそうしたSELECTがどのスタンバイサーバに行ってしまうか予測ができないため、アプリケーションは直接PostgreSQLに接続するということが必要でした。
そこでpgpool-II 3.4で導入されたのが、新しい負荷分散の指定方式です。
新しいパラメータ: app_name_redirect_preference_list
このパラメータにはカンマで区切った項目を複数記述します。一つの項目は、"アプリケーション名:DBノード番号"です。アプリケーション名には、PostgreSQLのアプリケーション名を指定します。たとえば、"psql"とかですね。正規表現も使えます。たとえば"abc.*"なら、"abc"で始まる任意のアプリケーション名となります。DBノード番号は、0, 1, 2などの数字を指定しますが、その他に"primary"ならプライマリサーバを、"standby"ならスタンバイサーバを指定したことになります。複数のスタンバイサーバがあるときは、「重み」に応じてどれかのスタンバイサーバが選択されます。
利用例: プライマリサーバが動いても常に検索クエリはスタンバイに投げる
先ほどのようなフェイルオーバでスタンバイサーバのDBノードが動いてしまって困るケースでは、以下のように指定することによって、常にスタンバイサーバだけに検索クエリを投げるようにできます。
app_name_redirect_preference_list: .*:standby
利用例: 重いアプリケーションの検索は常に特定のDBに投げる
"heavy_app"という名前のアプリケーションがあったとしましょう。このアプリケーションはデータ分析アプリで、非常に重い検索クエリを投げるので、専用のDBサーバを2台目のスタンバイに用意しました。このための設定は以下のようになります。
app_name_redirect_preference_list: heavy_app:2
利用例:マスタ更新アプリは常にプライマリサーバで検索する
マスターテーブル更新アプリケーションを考えましょう。このようなアプリケーションでは、更新した結果は、すぐに検索できないと登録データの整合性が崩れてしまうかもしれません。そうしたアプリでは、更新遅延の起こる可能性があるスタンバイサーバではなく、プライマリサーバを検索するようにしたいものです。以下のように設定しましょう。
app_name_redirect_preference_list: master_app:primary
利用例: マルチテナント的に、アプリケーションごとに専用の検索DBを用意したい
リソース管理の観点から、ユーザグループごとに使用する検索用のDBを分けたいことがあります。たとえば、ユーザグループAは"db_a", ユーザグループBは"db_b"を使用するものとします。しかし、同じサーバにA, Bがアクセスすると、リソースの取り合いになってしまいます。そこで、db_aへの検索はサーバ1に、db_bへのアクセスはサーバ2へとの分けることにしましょう。その場合の設定は以下のようになります。
database_redirect_preference_list: db_a:1,db_b:2
"database_redirect_preference_list"は、アプリケーション名ではなく、データベース名で負荷分散を定義するための設定です。
なお、app_name_redirect_preference_listとdatabase_redirect_preference_listの設定が矛盾する場合は、app_name_redirect_preference_listが優先されます。
yumリポジトリ公開
以上、pgpool-II 3.4の新機能をご紹介しました。
さて、ここでうれしいニュースがあります。以前からrpmファイルのダウンロードができるようにはなっていましたが、今回ようやくyumリポジトリの提供を開始する運びとなりました。rpmには、次のマイナーリリースを待たずにバグ修正も含まれているので、いち早く安定したpgpool-IIをご利用になれます。是非ご活用ください。
(2014年12月17日掲載)