
pgpool-II 3.2 の新機能 (2) オンメモリクエリキャッシュ
SRA OSS, Inc. 日本支社
安齋 希美
オンメモリクエリキャッシュとは?
端的に言うと、SELECT の結果をメモリ上にキャッシュとして保存しておいて、 同じ SELECT がきたときに、即座にそのキャッシュした結果を返すしくみです。 キャッシュが存在する場合には、SELECT 文をパース(構文解析)したり実際に実行したりしなくなるので、非常に高速です。
以下は、この機能に関する文書です。
場合によっては、飛躍的な性能向上が見られます。 更新がそんなに頻繁でなく、apache など同じユーザが同じ SELECT をたくさん発行するようなシステムでは、 大きな効果が得られるかもしれません。 特に、それが重い SELECT である場合には、めざましい改善が期待できるでしょう。
以下はその一例のグラフで、横軸は pgbench -S -c 10 -T 10 を実行した回数、 縦軸は TPS(Transactions Per Second / 1 秒間に実行したトランザクション数)です。
- SELECT のみのトランザクション
- ただし、わざと SELCT に苦戦するように、pgbench_accounts から主キーインデックスを削除した状態
- クライアント数 10
- 各回 10 秒ずつ実行
クエリキャッシュを使用していると、SELECT をたくさん実行するほど キャッシュから結果を取得することが増えるため、 毎回実際に SELECT している場合とくらべると、徐々に検索性能が上がって大きく差が出ます。
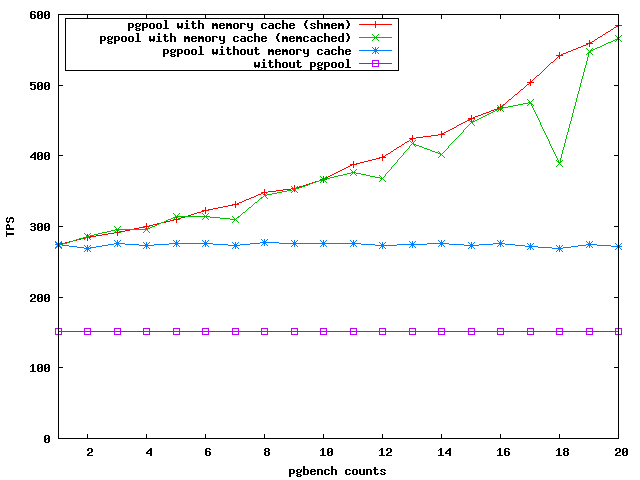
- ■ PostgreSQL + pgpool-II のロードバランスモード + 共有メモリでのクエリキャッシュ
- ■ PostgreSQL + pgpool-II のロードバランスモード + memcached でのクエリキャッシュ
- ■ PostgreSQL + pgpool-II のロードバランスモード
- ■ PostgreSQL 単体
| pgpool-II | 3.2 alpha1 | 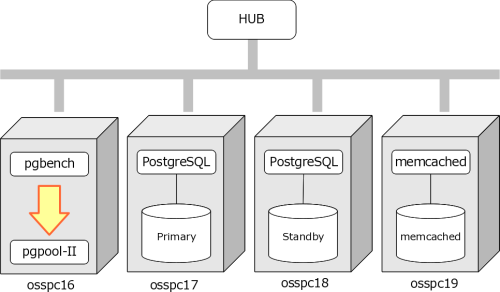 |
|---|---|---|
| PostgreSQL | 9.1.2 | |
| memcached | 1.4.13 | |
| マシンスペック(実サーバ / 4 台とも共通) | ||
| 品番 | DELL OPTIPLEX 755 | |
| OS | CentOS release 5.5 (final) | |
| CPU | Intel(R) Core(TM)2 Duo CPU E6550 @ 2.33GHz | |
| メモリ | 2 GB | |
仕様の概要
以下のような仕様になっています。
- キャッシュの保存先は、共有メモリ と memcached から選択できます。 → 詳しく見る(1.1)
- キャッシュする SELECT 結果の最大サイズを設定します。 → 詳しく見る(3.2)
- 一定秒数以上古くなったり、テーブルが更新されたら、キャッシュは自動的に無効になります。 → 詳しく見る(1.2)
- テーブルに INSERT/UPDATE/DELETE/TRUNCATE があったとき、DROP TABLE されたとき、 そのテーブルのキャッシュをすべて削除します。
- データベースが DROP DATABASE されたとき、そのデータベースの全テーブルのキャッシュを削除します。
- 失敗した SELECT や、トランザクション内の SELECT、current_timestamp のような実行するたびに 結果が異なる(IMMUTABLE でない)関数を含む SELECT は、キャッシュされません。 → 詳しく見る(マニュアル)
1. 設定方法
まず、オンメモリクエリキャッシュを使うには、そのフラグを有効にします。
memory_cache_enabled = on
1.1. キャッシュの保存先は?
キャッシュを保存する先を memqcache_method に指定します。
共有メモリであれば「shmem」、memcached であれば「memcached」を指定します (memcached を使う場合は、 pgpool-II のインストール の際 configure に「--with-memcached=path」を指定している必要があります)。
memqcache_method = 'shmem'
共有メモリと memcached で、それぞれ長所短所があります。
| 共有メモリ | memcached | |
|---|---|---|
| 速度 | ○ 高速です。 | △ ネットワーク通信のオーバヘッドがあります。 |
| キャッシュ上限 | △ 利用できる共有メモリのサイズの上限により、キャッシュできる量が限られることがあります。
|
○ 比較的自由に大きさを設定できます。 |
1.2. 自動無効化していい?
(1) 一定間隔
一定秒数より古いキャッシュを削除する、という寿命の設定を memqcache_expire で 指定することができます。0 秒を指定するとそのチェックをしなくなります。
memqcache_expire = 5
(2) テーブル更新時
デフォルトでは、テーブルが更新されたとき(例えば INSERT されたとき)は、 キャッシュしている SELECT の結果が変化する可能性があるため、そのテーブルのキャッシュをすべて削除します。
これは、memqcache_auto_cache_invalidation で on/off を切り替えることができます。
memqcache_auto_cache_invalidation = on
この 2 つの設定は、それぞれ独立しています。 たとえば、memqcache_expire を 0 秒にして memqcache_auto_cache_invalidation を on にしたときは、 一定間隔でのキャッシュの削除は行なわずテーブルの更新時にだけ削除されます。
1.3. どのテーブルをキャッシュ対象にする?
デフォルトでは、すべてのテーブルがキャッシュ対象になっていますが、一部だけ OK、あるいは一部だけ NG、 という情報を設定することができます。 「,」区切りで記述し、正規表現(語頭の「^」や語尾の「$」を抜いた形式)を使うこともできます。
一部だけキャッシュ OK にしたければ、ホワイトリスト にテーブル名を登録します。
white_memqcache_table_list = '.*_cache_ok'
一部だけキャッシュ NG にしたければ、ブラックリスト にテーブル名を登録します。
black_memqcache_table_list = '.*_cache_ng'
なお、デフォルトでは、一時テーブル(TEMP TABLE)や UNLOGGED テーブルや VIEW はキャッシュ対象になりませんが、 ホワイトリストに登録されていれば、それらをキャッシュ対象にすることができます。
2. 使ってみる!
2.1. クエリキャッシュを監視する
各クエリがどのノードで実行されたかをログに記録する、 log_per_node_statement を on にします。
log_per_node_statement = on
2.2. pgpool-II を起動する
pgpool-II を起動します。すでに起動している場合は reload します。
$ {installed_dir}/bin/pgpool -n \
-f {installed_dir}/etc/pgpool.conf \
> pgpool.log 2>&1
2.3. クエリキャッシュの挙動をみてみる
サンプルとして、テーブルを作成します。
$ createdb -p 9999 test $ psql -p 9999 test test=> CREATE TABLE table_cache_ok (a INT); CREATE TABLE test=> INSERT INTO table_cache_ok VALUES (1), (2), (3); INSERT 0 3 test=> SELECT * FROM table_cache_ok ORDER BY a; a --- 1 2 3 (3 rows)
1 回 SELECT を実行してみます。
test=> SELECT * FROM table_cache_ok WHERE a = 1; a --- 1 (1 row)
ログの log_per_node_statement の出力から、SELECT が実行されていることがわかります。
LOG: DB node id: 0 backend pid: 11203
statement: SELECT * FROM table_cache_ok WHERE a = 1;
もう一度同じ SELECT を実行します。
test=> SELECT * FROM table_cache_ok WHERE a = 1; a --- 1 (1 row)
ログを見ると今度は以下のメッセージがあり、キャッシュから結果を取得してきたことがわかります。
LOG: query result fetched from cache.
statement: SELECT * FROM table_cache_ok WHERE a = 1;
3. チューニング
しばらく運用したら、クエリキャッシュがちゃんと効果があるかをチェックします。
3.1. キャッシュヒット率は十分に高いか?
キャッシュヒット率は、 「SHOW pool_cache」で 確認することができます。
$ psql -p 9999 test test=> \x Expanded display is on. test=> SHOW pool_cache; -[ RECORD 1 ]---------------+--------- num_cache_hits | 281613 num_selects | 97742 cache_hit_ratio | 0.74 <= キャッシュヒット率 num_hash_entries | 1048576 used_hash_entries | 97718 num_cache_entries | 97718 used_cache_enrties_size | 11341894 free_cache_entries_size | 55766970 fragment_cache_entries_size | 0
あまりキャッシュが使われていないようであれば、 オンメモリクエリキャッシュ機能でキャッシュを登録・検索しているのは、 かえって無駄な処理になっていることになります。その場合は無理に使うのをやめましょう。 逆に、70 % 以上使われていたら、かなり有効に働いていると考えることができます。
3.2. 最大サイズは小さすぎないか?
以下のようなログメッセージが出ていないかを確認します。
LOG: DB node id: 0 backend pid: 17749
statement: SELECT * FROM pgbench_accounts ;
LOG: pool_add_temp_query_cache:
data size exceeds memqcache_maxcache.
current:983 requested:110 memq_maxcache:1024
これは、SELECT 結果が上限 memqcache_maxcache バイトより大きくて、 キャッシュとして保存しなかった、というメッセージです。 あまりに頻繁にこのメッセージが出ている場合は、上限をもう少し大きくすることを検討します。
3.3. キャッシュしていい SELECT か?
キャッシュされると都合の悪い SELECT がキャッシュされていることはないでしょうか? もし、特定の SELECT だけキャッシュしたくない、という場合には、 文頭に「/* NO QUERY CACHE */」をつけることで 除外されるようになります。
[ 1 回目 ]
LOG: DB node id: 0 backend pid: 18070
statement: /* NO QUERY CACHE */
SELECT * FROM table_cache_ok WHERE a = 1;
[ 2 回目 ]
LOG: DB node id: 0 backend pid: 18070
statement: /* NO QUERY CACHE */
SELECT * FROM table_cache_ok WHERE a = 1;
4. 内部構造
4.1. 処理の概要
ここでは、クエリキャッシュのしくみについて説明します。
- (1) クエリが来たときの処理
-
- 実行しようとしているクエリは SELECT で、かつ更新のあったトランザクションでない?
- 「クエリ文字列 + データベース名 + ユーザ名」から md5 ハッシュを作る。
※ 長大な SQL 文そのものでなく、短い文字列で保存する。
※ 参照権限がないテーブルのデータをキャッシュを経由して 他のユーザが参照できないようにするため、ユーザ名もキーにいれている。
※ 拡張問い合わせ の場合は、さらに Bind メッセージパラメータをつけたもので md5 ハッシュを作る。 - キャッシュが登録されていないか探す。
- 共有メモリ
- ハッシュインデックステーブル(md5 キーからキャッシュ ID へのマッピングを記録している)を参照して、 md5 キーから キャッシュ ID を取得する。
キャッシュ ID からキャッシュを見に行き、付加情報としてもっている キャッシュ登録時のタイムスタンプがmemqcache_expire秒以上経過していないか確認する。 もし経過していたら、キャッシュは無効としてここで削除する。 - memcached
- md5 キーをもとにキャッシュを見に行く。 キャッシュが
memqcache_expire秒以上古かったら、memcached がデータを返さない。
共有メモリ memcached 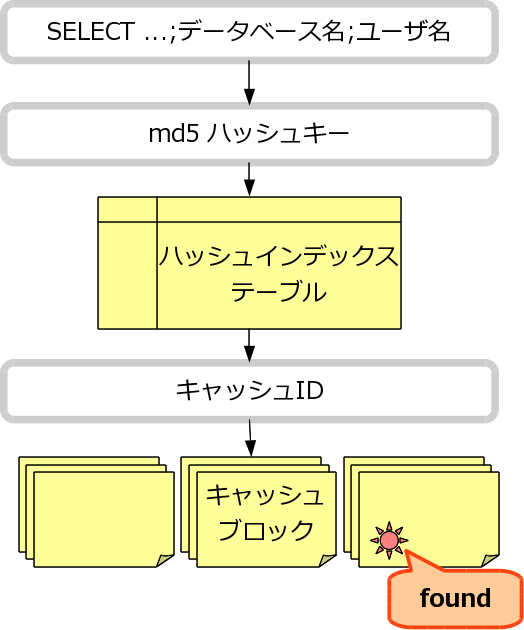
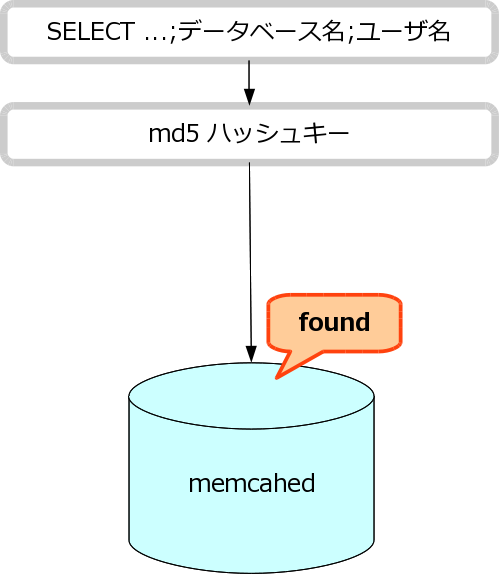
- キャッシュを取得できたら、それを返してここで終わり。
- 「クエリ文字列 + データベース名 + ユーザ名」から md5 ハッシュを作る。
- クエリをパースして、厳密にどんなクエリかを解析する。
- 実行しようとしているクエリは DROP DATABASE?
- 実行前に対象データベースの OID を取得しておく。
※ 実行完了時に、当該データベースのキャッシュをすべて削除したいが、 DROP DATABASE したあとではデータベースの OID が取得できないため。
- 実行前に対象データベースの OID を取得しておく。
- 実行しようとしているクエリは、本当に SELECT?
- マルチステートメントでない?、 対象のテーブルはホワイトリストに含まれる?、ブラックリストに含まれていない?、 IMMUTABLE でない関数は使われていない? 一時テーブルを使っていない? ... などのチェックの後、 キャッシュ OK フラグをたてる。
- FROM 句で指定されているテーブルの OID を取得する ( pgpool_regclass() 関数 かシステムカタログの pg_class を利用)。
- 実行しようとしているクエリは INSERT/UPDATE/DELETE/TRUNCATE?
- 対象となっているテーブルの OID を取得しておく。
- 実行しようとしているクエリは SELECT で、かつ更新のあったトランザクションでない?
- (2) クエリを実行
- (3) クエリを実行したあとの処理
-
- 実行したクエリは SELECT、かつ結果が
memqcache_maxcacheより小さく、キャッシュ OK フラグがたっている?- 共有メモリ ハッシュインデックステーブルを md5 キーで検索し、 すでに同じ SELECT のキャッシュが登録されていないかチェックする。
- キャッシュを共有メモリ or memcached に登録する。
- OID マップ の memqcache_oiddir/[DB の OID]/[テーブルの OID] のファイルに
- 共有メモリ キャッシュ ID(登録したブロックとブロック内の位置)
- memcached クエリから生成した md5 キー
※ この OID マップは、テーブル更新時のキャッシュ自動無効化 を高速に行なうために使われる。
- 実行したのは DROP DATABASE?
- memqcache_oiddir/[DB の OID] ディレクトリを削除する。
- 実行したのは INSERT/UPDATE/DELETE/TRUNCATE?
- テーブル更新時のキャッシュ自動無効化 が有効であれば、 OID マップ(memqcache_oiddir/[DB の OID]/[テーブルの OID] のファイル)にある キャッシュ ID / md5 キー から、キャッシュデータ本体を削除する。
また OID マップファイル自体も削除する。
共有メモリ memcached 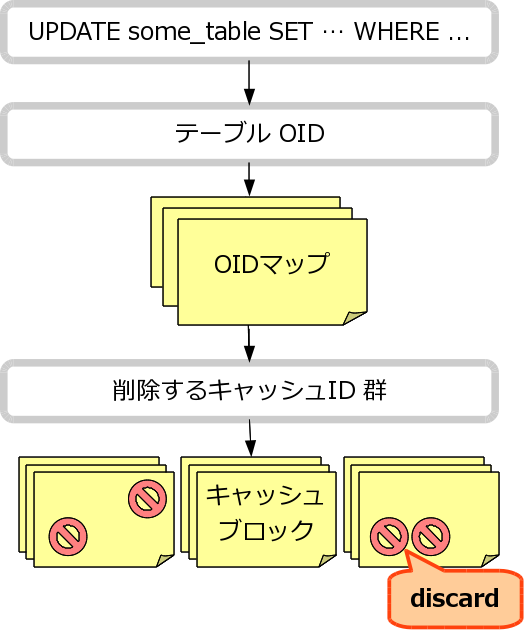

- テーブル更新時のキャッシュ自動無効化 が有効であれば、 OID マップ(memqcache_oiddir/[DB の OID]/[テーブルの OID] のファイル)にある キャッシュ ID / md5 キー から、キャッシュデータ本体を削除する。
- 実行したクエリは SELECT、かつ結果が
4.2. OID マップ
更新処理が発生した時にキャッシュの削除処理を高速化するために、 「OID マップ」というインデックスのようなファイルを、テーブルごとに作っています。
この OID マップは、 memqcache_oiddir パラメータでパスを指定することができ、 その下でデータベースごとのディレクトリ(ディレクトリ名はデータベースの OID)にわかれ、 さらにテーブルごとのファイル(ファイル名はテーブルの OID)に分かれています。
各テーブルごとのファイルには、共有メモリ使用時は キャッシュ ID、 memcached 使用時は md5 キーが記録されていて、キャッシュデータ本体へのポインタとして使われます。
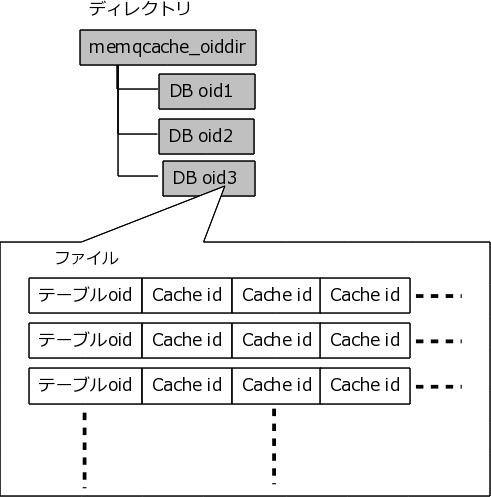
OID マップは、テーブル更新時のキャッシュ自動無効化 を有効にしている場合に、 INSERT/UPDATE/DELETE/TRUNCATE によるテーブルの更新があってキャッシュを削除する際に、 どのキャッシュを削除すればいいかを高速に探すのに役立ちます。
なお、複数のテーブルを JOIN している場合は、同じキャッシュ ID / md5 キーが各テーブルのファイルに書き込まれます。
4.3. 共有メモリ内のデータ構造
実際のキャッシュデータは、以下のような構造で保存されています。 これは、PostgreSQL のデータブロック(データベースクラスタのディレクトリの base/ 以下)の構造と類似していて、 頭からヘッダ情報を詰めていき、後ろから実際のデータ本体を詰めていきます。
この 1 ブロックのサイズは memqcache_cache_block_size で指定することができ(512 バイト以上、デフォルトでは 1 MB)、 SELECT 結果は 1 ブロックに詰め込めるだけ詰め込まれます。 ひとつの SELECT 結果は複数のブロックにまたがって登録できないため、このサイズを超えたものは キャッシュされないことになります。
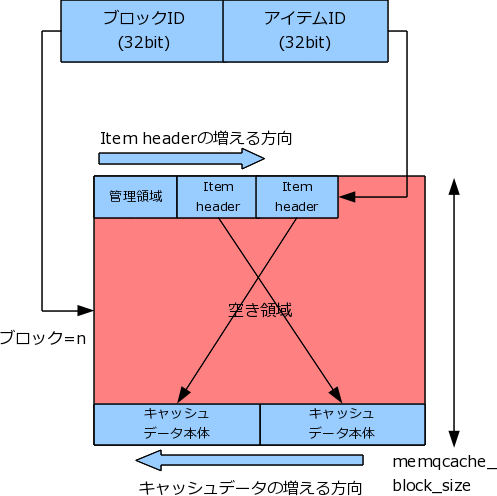
この「ブロック ID + アイテム ID」組み合わせがキャッシュ ID となり、 OID マップやハッシュインデックステーブルに使われています。
そのほか指定できるものとしては、
- 共有メモリのうちキャッシュ登録先として使う領域サイズを指定する
memqcache_total_size
(デフォルトは 128 MB) - ハッシュインデックステーブルに持つキー情報の最大数を指定する
memqcache_max_num_cache
(デフォルトは 1,000,000 こ、使われる領域サイズとしては 1000,000 * 48 バイト = 約 45.8 MB)
があります。
4.4. pgpool 再起動したときにキャッシュを再利用する
pgpool-II を起動・再起動したとき、前回保存された OID マップを削除しますが、 キャッシュストレージに memcached を使っているときは、それを行ないません。 そうすることでキャッシュ結果を再利用することができます。
共有メモリを使っているときと同じように削除したい場合は、pgpool-II の起動オプション 「-C (--clear-oidmaps)」 を使います。
$ {installed_dir}/bin/pgpool -n -C \
-f {installed_dir}/etc/pgpool.conf \
> pgpool.log 2>&1
なお、逆に pgpool-II が稼働したまま memcached を停止したときや再起動している間は、 クエリキャッシュを使うことができないため、実際に SELECT を実行して結果を返します。
(2012 年 9 月 3 日掲載)