
文字列型の使い分け
NTT オープンソースソフトウェアセンタ 板垣 貴裕
PostgreSQL には文字列型として char, varchar, text など複数がありますが、使い分けはあるでしょうか? データ型を一覧としてまとめ、文字列型それぞれの特徴を解説していきます。
PostgreSQL のデータ型
まず、文字列型も含めた PostgreSQL の基本データ型を整理してみます。他にも幾何データ型やユーザ定義型のサポートもありますが、もっとも良く使うのは、これらの基本データ型でしょう(表1)。「サイズ」はデータ型のバイト数、「配置」は配置境界の条件となるバイト数です。データ型を決める際には、十分な精度を持つ、最も格納効率のよいものを選ぶのが良いでしょう。
ここで、配置境界 (alignment) とは、そのバイト数に揃うようにメモリ上でデータを配置する必要がある境界です。例えば (integer, smallint, bigint) というデータをデータブロックに保持する場合、最初から並べていくと bigint が適切な境界 (8byte) に並びません。そのため、bigint の前に 2 byte のパディングが追加され、合計で 4 + 2 + (2) + 8 = 16 byte になります。最初のデータはキリのよい位置 (多くの環境では 8byte 境界) から始まるとして計算してください。文字列型などの可変長型の場合には、定義ではなく実際のデータサイズ数に基づいて計算されます。また、末尾に 8byte 未満の領域が残っていたとしても、そこは他の用途には使えないデッドスペースになります。データ効率的に格納することにこだわるのならば、列の並びも調整すると良いかもしれません。
| 型 | 標準名 | 別名 | サイズ | 配置 | バージョン |
|---|---|---|---|---|---|
| 文字列 | |||||
| 固定長文字列 | character(n) | char(n) | (1 or 4) + n | 1 | 8.3 ~ |
| 4 + n | 4 | ~ 8.2 | |||
| 可変長文字列 | character varying(n) | varchar(n), text | (1 or 4) + n | 1 | 8.3 ~ |
| 4 + n | 4 | ~ 8.2 | |||
| 識別子 | name | 64 | 1 | ||
| 1文字 | "char" | 1 | 1 | ||
| 数値 | |||||
| 2byte 整数 | smallint | int2 | 2 | 2 | |
| 4byte 整数 | integer | int4, int | 4 | 4 | |
| 8byte 整数 | bigint | int8 | 8 | 8 | |
| 4byte 実数 | real | float4 | 4 | 4 | |
| 8byte 実数 | double precision | float8, float | 8 | 8 | |
| 10進実数 | decimal, numeric | 3 + (n / 2) | 1 | 9.1 ~ | |
| 5 + (n / 2) | 1 | 8.3 ~ | |||
| 8 + (n / 2) | 4 | ~ 8.2 | |||
| その他 | |||||
| 日時 | timestamp | 8 | 8 | ||
| 年月日 | date | 4 | 4 | ||
| 期間 | interval | 16 | 8 | ||
| 真偽値 | boolean | bool | 1 | 1 | |
また、PostgreSQL にはいわゆる CLOB, BLOB のような巨大データ専用の型は存在せず、1GB までであれば text や bytea 型をそのまま使えます。1GB を超える場合はラージオブジェクトも利用できますが、アクセスや管理の方法にクセがあるためお奨めできません。数MBまでは text や bytea を使い、それを超えるようなら外部ファイルとして保持したほうが、むしろ安心して運用できるかと思います。
char と varchar, text の比較
PostgreSQL の文字列は以下のような特徴があります。
- 1. char(n) や varchar(n) の 'n' は「文字数」を表す
- 他のデータベースではバイト数を表すものもあるので注意しましょう。
- 2. char(n) は n 文字になるように末尾に空白を追加して保持する
- n 文字ぴったりで無い限り、末尾の空白のぶんだけ varchar や text よりもサイズが大きくなります。
- 3. text と varchar の相互変換は処理不要。char とは変換処理が必要
- varchar は文字数制限のある text 型とほぼ等価で、お互いの変換には特に追加の処理は要りません。一方、char は末尾の空白を扱い計算コストがかかります。
- 4. 文字列関数の多くは、引数や返値が text として定義されている
- char を文字列処理関数に渡すと、text への暗黙的に変換されます。
上記のように、char 型にはほとんど利点がありません。末尾の空白のぶんだけサイズが大きく、text との変換のための処理が必要であり、完全な固定長 (バイトサイズ一定) でも無いので配置決めの際の利点もありません。さらに、PostgreSQL は追記型ですから、「後から文字数が増えても良いよう予め余白を確保しておく」効果もありません (その目的には fillfactor を設定しましょう)。
実際、下記の実験結果のように、char だけは明らかに計算が遅くなります。varchar と text は 180ms 程度なのに対し、char では 230ms 程度かかっています。to_number() 関数の引数は to_number(text, text) のみです。varchar 型の内部表現は text 型とまったく同一なので型変換処理が行われないのに対し、char 型では末尾の空白を除去するため文字列のコピーが発生しているためと考えられます。
=# CREATE TABLE test AS
SELECT n::char(10) AS c,
n::varchar(10) AS v,
n::text AS t
FROM (SELECT to_char(i, 'FM0000000000') AS n
FROM generate_series(1, 100000) AS i) AS tmp;
=# VACUUM test;
=# CHECKPOINT;
=# \timing
=# SELECT sum(to_number(v, '0000000000')) FROM test;
Time: 188.867 ms
=# SELECT sum(to_number(t, '0000000000')) FROM test;
Time: 183.695 ms
=# SELECT sum(to_number(c, '0000000000')) FROM test;
Time: 228.975 ms
text と varchar の比較
text と varchar に関しては、データベース自体の効率面では、それほど意識的に使い分ける必要は無いでしょう。varchar では文字数を制限することができますが、文字数制限くらいでは壊れたデータの投入を抑止するのは不十分です。
きちんと判定したいならば、CHECK 制約で正規表現を使ったチェックなどのほうが適します。CHECK 制約を使うと、INSERT, UPDATE では余分なコストがかかりますが、参照処理の邪魔にはなりません。もし同じ入力チェックを行う型が複数ある場合には、先に DOMAIN を定義しても良いでしょう。
-- CHECK 制約を使った入力チェック。
=# CREATE TABLE tbl (t text CHECK (t ~ '^[0-9]{5}$'));
=# INSERT INTO tbl VALUES('12345');
INSERT 0 1
=# INSERT INTO tbl VALUES('1234');
ERROR: new row for relation "tbl" violates check constraint "tbl_t_check"
=# INSERT INTO tbl VALUES('123456');
ERROR: new row for relation "tbl" violates check constraint "tbl_t_check"
=# INSERT INTO tbl VALUES('1234A');
ERROR: new row for relation "tbl" violates check constraint "tbl_t_check"
このように、データベース内部では text と varchar には扱われ方に大きな差はありませんが、外部ツールや設計書と連携する際には、区別して扱うと便利な場合もあります。
- varchar ではテーブル定義を見るとデータ量の見積もりができる
- varchar の文字数を必要量+α 程度に設定しておくと、テーブル定義と想定する行数が判れば、データ量の見積もりができます。一方、text では長さ情報が完全に失われてしまいます。text を使う場合には、想定される文字数などをコメントとして残しておくと後々役に立つかもしれません。
- データアクセスツールでのテキストボックスで 一行 vs. 複数行
- データアクセスツールでは、使われる型に応じてデータ入力フォームの形状を変更するものがあります。ツールにも依存しますが、varchar では一行入力のテキストボックスが、text では複数行テキストボックスを使うものもあるようです。データアクセスツールを使う場合には、入力する文字列の長さに応じて、データ型を使い分けておくと良いかもしれません。phpPgAdmin の例を 図1 に示します。
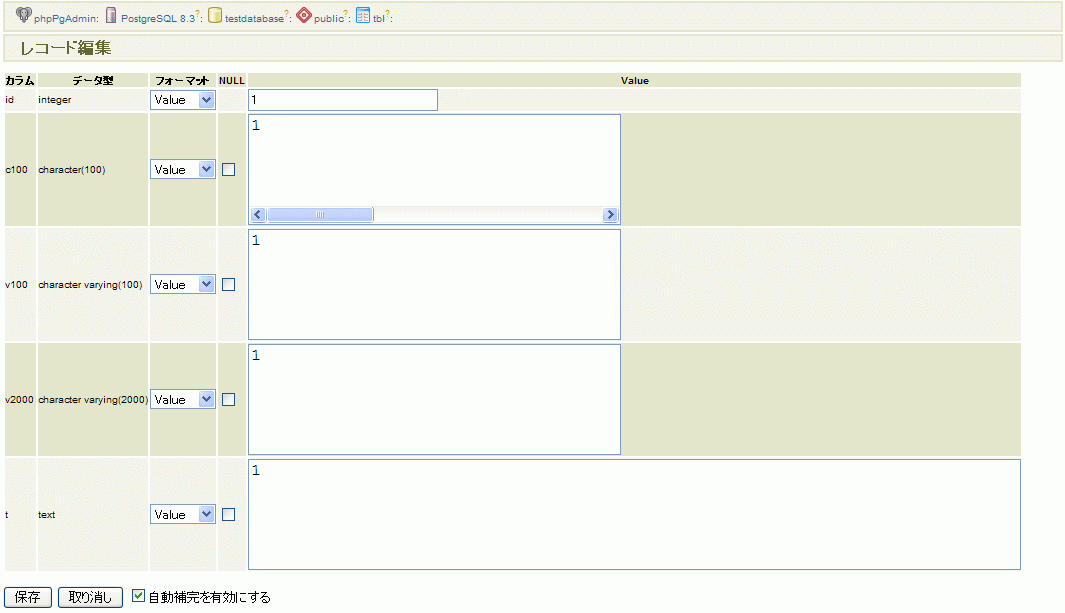
図1 : phpPgAdminでのデータ型による表示の違い。
char, varchar では狭いフィールドで / text 型では広いフィールドで値を入力するようになっています。
その他の文字列型
name はシステムテーブルで識別子 (テーブル名など) に使われる固定長文字列ですのでユーザが使う機会は無いでしょう。ただ、「オブジェクト名は 63 byte まで」という制約は頭の片隅に覚えておくと、日本語の名前を付ける場合などで役に立つかもしれません。
同様に、"char" もシステムテーブル用のシングルバイト1文字ですが、もし1バイトのフラグのような列を多用する場合には、サイズの節約のため一考の余地はあります。smallint や char(1) では 2 byte (以上) になるため、数10種類程度の列挙値であれば "char" が最も効率が良くなります。ちなみに、8.3 以降で利用できる列挙型 (CREATE ENUM) は内部的には oid 型 (4 byte) です。
ゼロ詰め形式
先頭にゼロを付加したいというためだけに文字列型を使っている例も良く目にするのですが、これは性能や格納効率の面ではもったいないです。文字列型と比べると、整数型のほうが高速に計算できますし、サイズの面でも有利な場合が多いでしょう。ゼロ詰めした値が欲しい場合には、データベースには整数型として格納し、データを取得する際に必要に応じて to_char() でゼロ詰めすると効率的です。
-- 4桁でゼロ詰め SELECT to_char(id, 'FM0000') FROM item;
FM が無い場合、先頭に空白文字が追加されます。 負の値の場合は、この空白の位置がマイナス記号になります。
残念ながら MySQL の ZEROFILL のように、デフォルトの表示モードを設定することはできませんので、毎回 to_char() での変換が必要です。もし変換を記述するのが面倒であれば、ビューを定義するなどで対応してください。
8.3以降のサイズについて
PostgreSQL 8.3 以降であれば文字列サイズに応じてヘッダサイズが調整されます。126 byte まではヘッダ 1 byte の短形式、それ以上は 4 byte の長形式になります。配置境界が 4byte から 1byte に緩和されたことも含め、短形式の文字列は PostgreSQL 8.3 での性能向上に一役買っています。場合によっては 20% 程度もデータサイズを縮小できる場合もあるようです。
=# SELECT length(t), pg_column_size(t) FROM tbl;
length | pg_column_size
--------+----------------
126 | 127
127 | 131
(2 rows)
この際の配置イメージは図2のようになります。短形式のヘッダの余り1bitは長形式との区別のために、長形式の余り2bitは TOAST 状態を表すために使われています。
| 番地 | 1 | 2 | 3 | 4 | 5 | ... | 127 | 128 | 129 | 130 | 131 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 短形式 | 127 (7bit) | 文字 1 |
文字 2 |
文字 3 |
文字 4 |
... | 文字 126 |
||||
| 長形式 | 131 (30bit) | 文字 1 |
... | 文字 123 |
文字 124 |
文字 125 |
文字 126 |
文字 127 |
|||
まとめ
データベースで扱うデータ型の中で最も多用されるのは文字列や数値でしょう。効率的にデータを格納するには、データ型の選択が重要になります。まさに、チリも積もれば山となる、です。
型の選択には特に厳密なルールはありませんが、例えば、以下のような優先順序で文字列型を選ぶような基準を作ってみてはいかがでしょうか:
- 1. 一定数の候補から選択では、整数型, 列挙型, "char" を使う。
- 都道府県名など候補が決まっている場合には、文字列ではなくIDとして格納すると効率的です。
- 2. 文字として数値しか表れないのであれば、整数型を使う。
- ゼロ詰めしたい場合には、取得時に to_char() で書式を整えます。
- 3. 200文字以内ならば varchar 型
- 比較的短い文字列であることをスキーマ内で表明し、管理性や外部ツールとの連携性を高めます。ここでの「200文字」は特に根拠のある値ではありませんが、「設定上限を超える入力はありえない」と考えられる場合には「短い」と解釈できます。例えば、「人名」であれば 200 文字は十分ですが、「自己紹介」であれば上限は予想できないので短くないと扱って良いかと思います。
- 4. それ以外は text 型
- 長い文字列ならば、特に文字数を制限する必要も無いので text 型を使います。