
現場で役立つ実践ノウハウWeb開発の「べし」「べからず」(試験編)
~性能を最大限に引き出すための設計・開発・運用~
永安 悟史
本記事は、技術評論社 WEB+DB PRESS Vol.63 で掲載されたものを、著者と出版社の許可を得て転載したものです。なお、一部 記述に変更のある箇所もあります。
【試験】サービス開始に向けて、確認・記録する
データベース開発の試験フェーズでは、機能的な動作確認は当然ながら、パフォーマンスやバックアップ/リストアなどの、いわゆる「非機能試験」を行うことになります。本節では、データベース特有の試験について、いくつかのポイントを解説します。
【べし】 SQLの実行計画(EXPLAIN)を確認すべし
まず、アプリケーションから実行されるSQLは、EXPLAINコマンドなどを用いて、実行計画を確認しておく必要があります(リスト5)。動的なSQL(アプリケーションの内部でSQL文を組み立てるようなケース)の場合は、SQLの実行ログを取得して、実行されているSQL文の実行計画を確認しておく必要があります。
実際には、試験フェーズというより、データベースの設計や開発を行っている段階で、少しずつEXPLAINの実行を行うのが望ましいのですが(後工程では修正がより難しくなるため)、運用中にパフォーマンスチューニングが必要になった場合、「そもそもどうなっていたのか」という記録が残っていないと、性能改善にも大きな困難を伴いますので、必ず確認するようにしましょう。
SQLのパフォーマンスチューニングにおいては、EXPLAINで表示した実行計画のうち、実行コストがかかっている項目(多くの場合はテーブルスキャンやソート)を中心にチューニングしていくことになります 注3。
リスト5 PostgreSQLの実行計画を表示するEXPLAIN ANALYZEコマンド
DBT1=# EXPLAIN ANALYZE SELECT count(*) FROM orders;
QUERY PLAN
--------------------------------------------------------------------------
Aggregate (cost=81909.50..81909.51 rows=1 width=0)
(actual time=14300.250..14300.251 rows=1 loops=1)
-> Seq Scan on orders (cost=0.00..75427.40 rows=2592840 width=0)
(actual time=0.060..12343.583 rows=2592139 loops=1)
Total runtime: 14310.862 ms
(3 rows)
参考
- 第14章 性能に関するヒント 14.1. EXPLAINの利用
- MySQL 5.1 リファレンスマニュアル :: 6 最適化 :: 6.2 SELECTステートメントおよびその他のクエリの最適化 :: 6.2.1 EXPLAINを使用して、クエリを最適化する
注3:EXPLAINの具体的な読み方は、各RDBMS製品のマニュアルを参照してください。
【べし】 テストデータ作成の際はデータの中身を考慮すべし
サービス開始の前には、テストデータを使って性能試験を行うことが多いと思います。このとき、テストデータの内容、作成方法に気をつけなければなりません。特に「カーディナリティ」(データの偏り)について、注意を払う必要があります。
「理想的なテストデータ」というのは、実際に蓄積される(された)データです。特にシステムの(新規開発ではなく)更改の場合は、以前のシステムで利用していたデータがあると思いますので、そのようなデータを使って(一部は無効化しておくにせよ)性能試験ができるのであればベストと言えます。
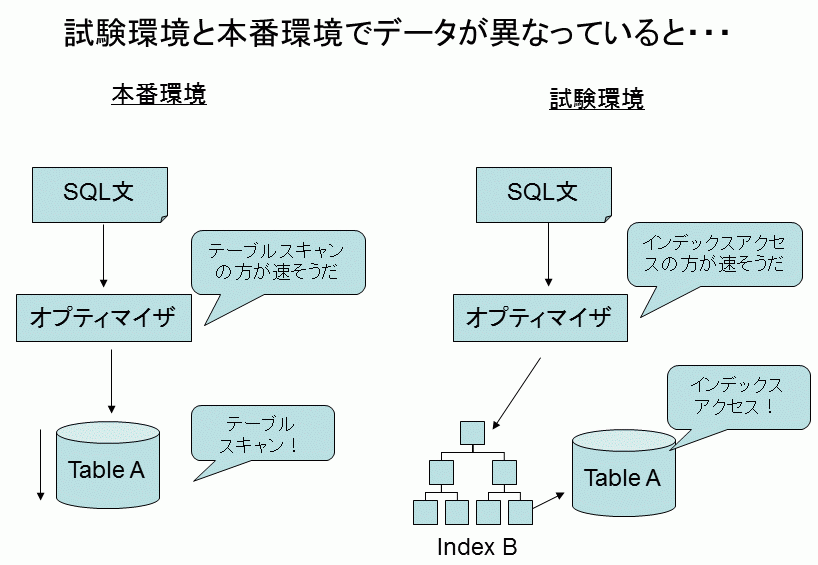
テストデータを作成する場合、ほとんどすべて同じ値を使ったり、逆にランダムにデータを作成すると思います。しかし、このように作成したデータが本番環境のデータと著しく異なっているには注意が必要です。 というのは、インデックスの利用可否などの実行計画はデータの分布(偏り)によって変化するため(これを判断しているのはRDBMSの最適化処理/オプティマイザです)、試験環境と本番環境のデータの違いによって実行計画が変わってしまった場合、性能試験の結果がほとんど意味がなくなってしまうのです(図6)。
そのため、できれば本番環境のデータを使って性能試験をする、それが無理であれば、EXPLAINで実行計画を(試験時に)きちんと取得しておき、本番環境で起こり得る実行計画の差異に備えておくことが賢明であると言えます。
【べからず】 パフォーマンスチューニングは「100%」を目指すべからず
データベースのパフォーマンス試験、チューニングを行う場合に、「どのレベルを目指すのか」ということを事前に決めておくことは非常に重要です。パフォーマンスチューニングをする際には、投入するコスト(多くの場合はエンジニアの人件費)と、チューニングによって得られる効果を考えなければなりません。
性能の指標を決める場合、多くの場合は「レスポンスタイムXXミリ秒以内、スループットYY、トランザクション/秒以上」といった指標を決めますが、このとき、「実行したSQLのうち、90%以上(90%ile)が指標をクリアすること」といった統計的な指標を含めることが現実的です。
データベースのソフトウェアは複雑であり、さまざまな処理が同時並行的に行われていますので(チェックポイント処理など)、ある一定の確率で(タイミング的に)想定している性能を下回るケースが出てしまいます。
「すべてのSQLが」のように「100%」を目指すことは目標としては「美しい」のですが、「90%できていること」を「100%できるようにする」ことには、一般的に多くのコスト(時間、労力など)を伴うため、現実的とはいえません。
そのため、想定している性能からはみ出す「異常値」の存在を認め、性能の指標を決める際には「90%ile」や「95%ile」などの統計的な指標を含めておくことが望ましいと言えます。
参考
【べし】 バックアップ/リストアの試験を「必ず」行い手順書を残すべし
データベースのバックアップは、通常のファイルのバックアップと比べて複雑なものになりがちです。データファイル、ログファイル、設定ファイルなどを、それぞれ適切なタイミング、適切な手順で取得できていないと、正しくリストアできるバックアップセットになりません。また、データやログの量に応じてバックアップやリストアにかかる時間は大きく変わってきます。
そのため、バックアップおよびリストアについては、必ずその手順を明らかにしてバックアップ/リストア試験(リハーサル)を行い、実施可能な手順を「手順書」という形で残しておく必要があります。それと同時に「所要時間」をきちんと確認しておく必要があります。
リストアやリカバリは、「いつ実施することになるかわからない」というところに、その不安の原因があります。また、チームで開発、運用している場合は、復旧作業を行うのが必ずしも自分であるとは限りません。
障害発生時の「最後の砦」であるはずのバックアップ/リストアが、リスク(不確実性)になってしまっては困ります。いざというときにある程度安心して落ち着いて作業ができるよう、バックアップ/リストアの確実性を高めるためにも、必ず試験を行い、その手順を手順書としてきちんと残すようにしましょう。
参考
次回は、運用編です。